

- 姓名: 陈诗宇
- 学号: 24300240030
用 ida 打开 password 文件,发现这是一个 AArch64 ELF 静态链接程序,没有剥离符号,所以分析起来比较方便。直接搜符号表可以看到 flag1_enc、flag2_enc、flag3_enc、print_flag3 等有意义的名字。
程序的 main 函数逻辑很直白:读取 24 个字符的密码输入,然后分 3 个阶段分别验证前 8 位、中间 8 位、后 8 位。每个阶段独立验证,通过就输出对应的 flag 片段。
第一阶段是简单的异或验证:
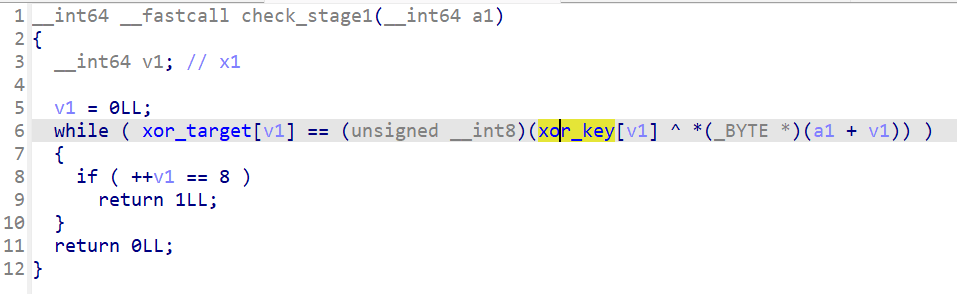
// 伪代码还原 for (i = 0; i < 8; i++) { if (xor_target[i] != (xor_key[i] ^ password[i])) { // stage 1 failed } }
从 .rodata 段提取出两组数据:
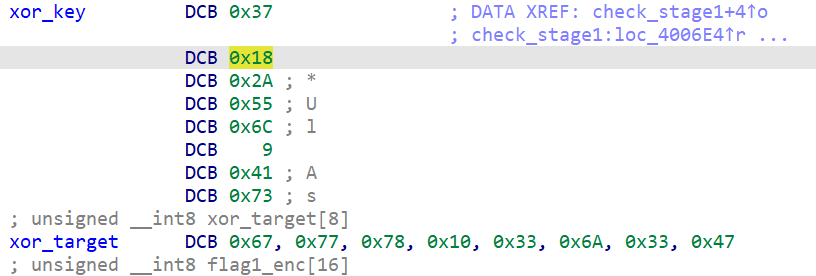
| 符号 | hex 值 |
|---|---|
| xor_key | 37 18 2a 55 6c 09 41 73 |
| xor_target | 67 77 78 10 33 6a 33 47 |
逆向很直接,password[i] = xor_target[i] ^ xor_key[i],逐字节异或就得到:PoRE_cr4
Flag 第一部分的解密也很简单,flag1_enc 每个字节减 5 得到 flag{X0r_。
第二阶段用的是乘法和加法变换:
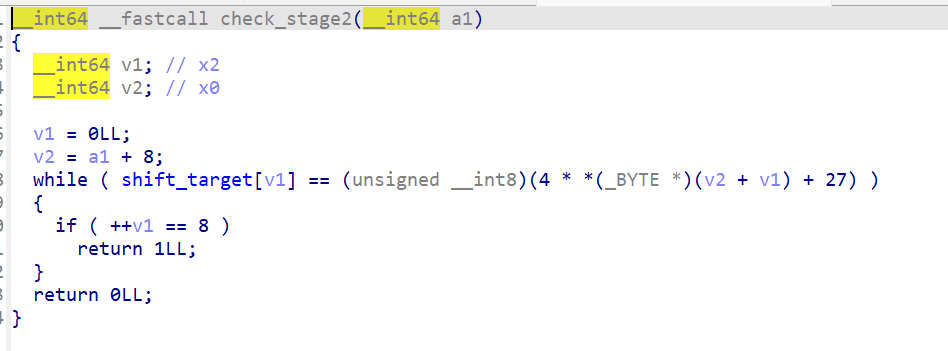
for (i = 0; i < 8; i++) { if (shift_target[i] != ((password[8+i] * 4 + 0x1b) & 0xff)) { // stage 2 failed } }
这个没法直接逆运算(乘以 4 之后取低 8 位会丢失信息),所以我写了个脚本遍历所有可打印 ASCII 字符,对每个位置找满足等式的字符。
shift_target = [0xa7, 0x47, 0x03, 0xe7, 0x97, 0x63, 0xe7, 0xf3] for i in range(8): for c in range(0x20, 0x7f): if (c * 4 + 0x1b) & 0xff == shift_target[i]: print(chr(c), end='') break
解出来是 #K:3_R36。Flag 第二部分是 flag2_enc 每字节异或 0x42 得到 b1t_Sh1fT_。
第三阶段对偶数和奇数位置用了不同的变换:
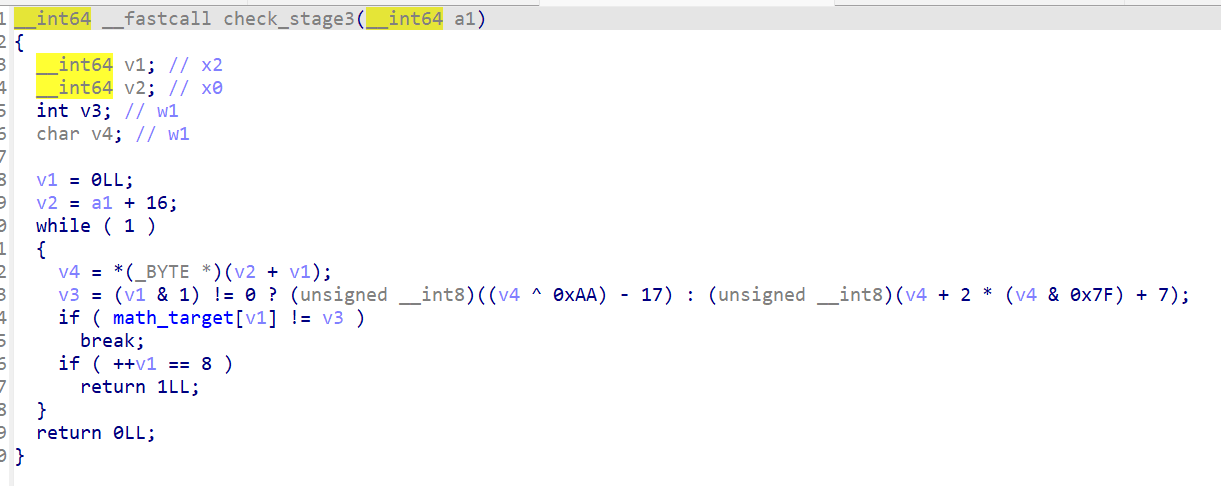
for (i = 0; i < 8; i++) { if (i % 2 == 0) // 偶数位 check = (password[16+i] * 3 + 7) & 0xff; else // 奇数位 check = ((password[16+i] ^ 0xaa) - 0x11) & 0xff; if (math_target[i] != check) { /* failed */ } }
同样暴力枚举可打印字符,解出 Eng1n33R。Flag 第三部分是 flag3_enc 每字节减 0x0d 得到 m4th_FuN!}。
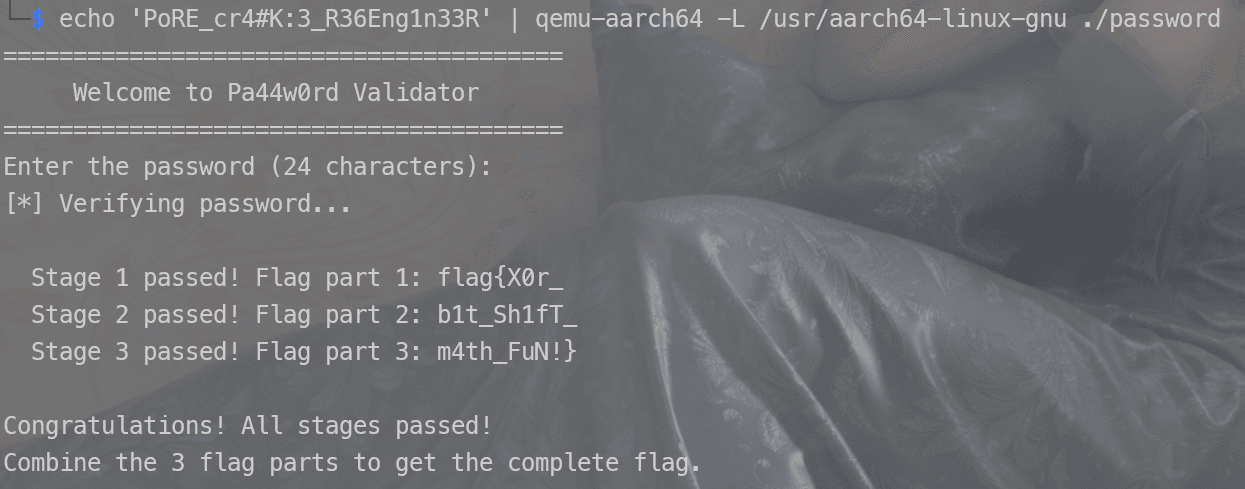
$ echo 'PoRE_cr4#K:3_R36Eng1n33R' | qemu-aarch64 -L /usr/aarch64-linux-gnu ./password ======================================== Welcome to Pa44w0rd Validator ======================================== Enter the password (24 characters): [*] Verifying password... Stage 1 passed! Flag part 1: flag{X0r_ Stage 2 passed! Flag part 2: b1t_Sh1fT_ Stage 3 passed! Flag part 3: m4th_FuN!} Congratulations! All stages passed!
- flag:
flag{X0r_b1t_Sh1fT_m4th_FuN!}
night_market_gate 是一个动态链接的 AArch64 程序,已 stripped。
首先通过字符搜索一些信息比如Night Market,找到main,是sub_4011B0,反汇编分析
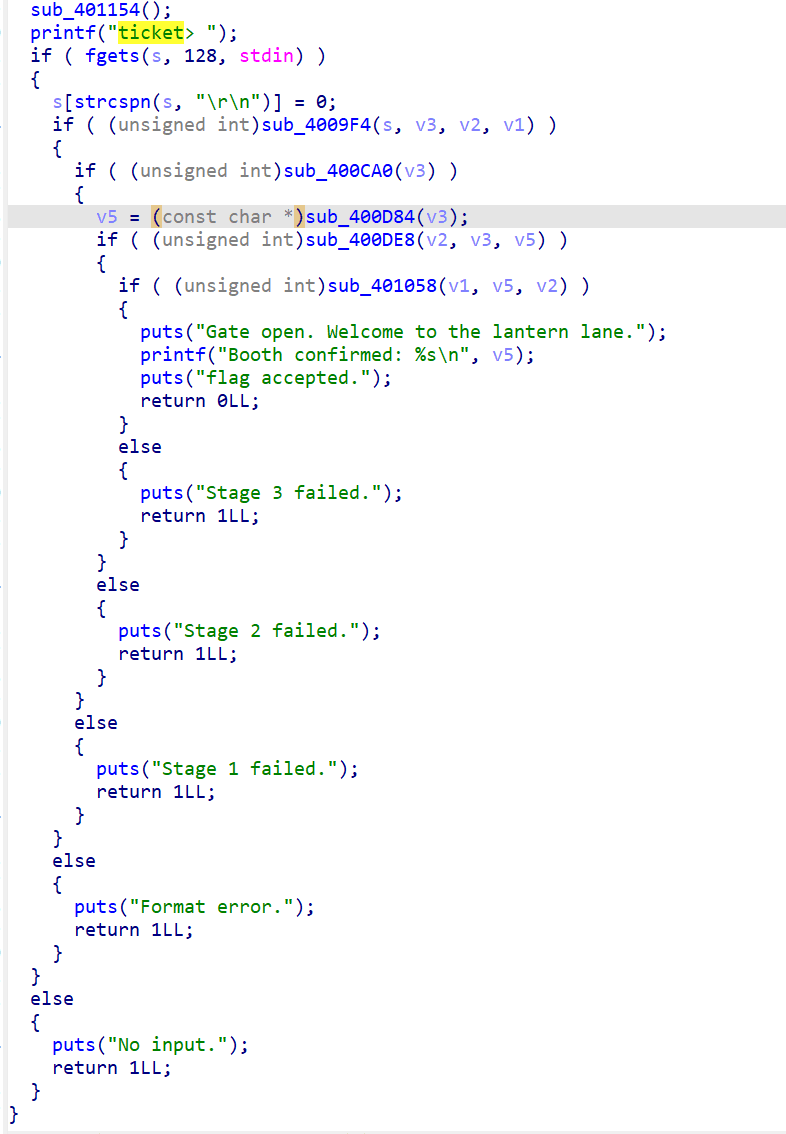
通过分析main可以得到每个stage对应的校验函数如下:
| sub_400CA0 | 0x400CA0 | Stage 1:route 校验 |
|---|---|---|
| sub_400D84 | 0x400D84 | booth 选择 |
| sub_400DE8 | 0x400DE8 | Stage 2:seat 校验 |
| sub_401058 | 0x401058 | Stage 3:path 校验(调用 sub_400F1C) |
| sub_400F1C | 0x400F1C | 状态机图遍历 |
sub_400CA0反汇编如下

校验函数对 route 的每个字符做变换后与目标数组比较:
// 目标数组在 0x4014e8: "GLJVf" -> {0x47, 0x4c, 0x4a, 0x56, 0x66} for (i = 0; i < 5; i++) { result = (i*2 + ((i*3 + 0x25) ^ route[i]) + 1) & 0xff; if (result != target[i]) fail; }
逆向:route[i] = (i*3 + 0x25) ^ (target[i] - i*2 - 1)
手算每一位:
- i=0: (0+0x25) ^ (0x47-0-1) = 0x25 ^ 0x46 = 0x63 = 'c'
- i=1: (3+0x25) ^ (0x4c-2-1) = 0x28 ^ 0x49 = 0x61 = 'a'
- i=2: (6+0x25) ^ (0x4a-4-1) = 0x2b ^ 0x45 = 0x6e = 'n'
- i=3: (9+0x25) ^ (0x56-6-1) = 0x2e ^ 0x4f = 0x61 = 'a'
- i=4: (12+0x25) ^ (0x66-8-1) = 0x31 ^ 0x5d = 0x6c = 'l'
route = canal
sub_400D84反汇编如下
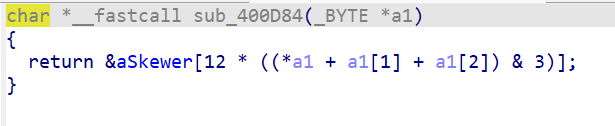
程序用 route 前 3 个字符之和决定选哪个 booth:
idx = (route[0] + route[1] + route[2]) & 3; // 'c' + 'a' + 'n' = 99 + 97 + 110 = 306 // 306 & 3 = 0 ... 其实不对
306 % 4 = 2,选中第 3 个 booth。
 在 0x401330 处有 4 个 booth 结构:skewer, lotus, bubble, ginger,每个 12 字节。idx=2 选中 bubble。
在 0x401330 处有 4 个 booth 结构:skewer, lotus, bubble, ginger,每个 12 字节。idx=2 选中 bubble。
booth "bubble" 的关键字段:booth[8]=1, booth[9]=4。
sub_400DE8反编译如下
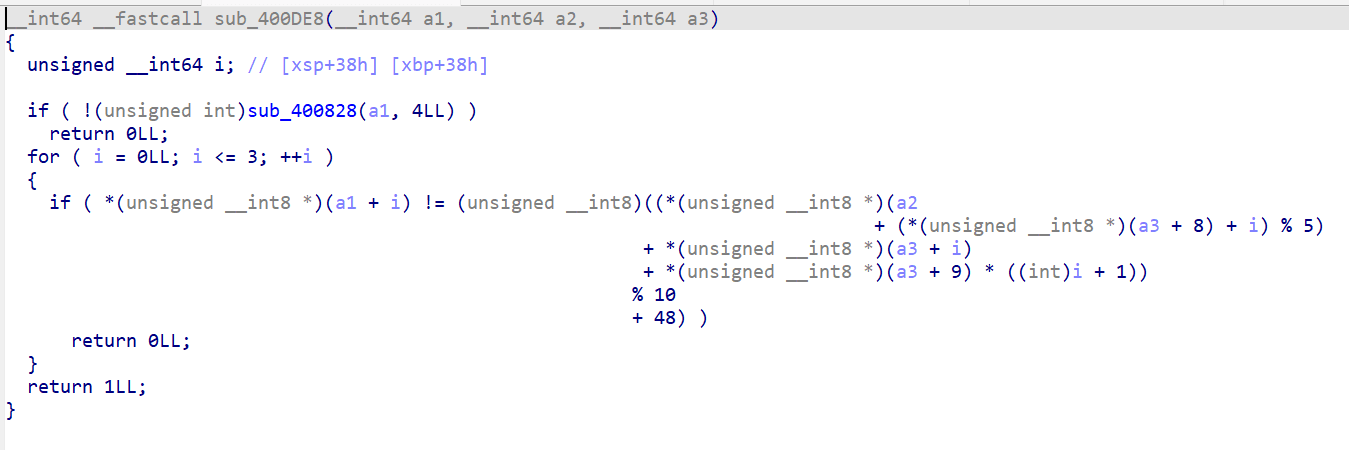
for (i = 0; i < 4; i++) { seat[i] = (route[(booth[8]+i) % 5] + booth[i] + booth[9]*(i+1)) % 10 + '0'; }
代入 booth[8]=1, booth[9]=4, route="canal", booth="bubble":
- i=0: route[1%5]='a'(97) + 'b'(98) + 4*1=4 => (97+98+4)%10+48 = 199%10+48 = 9+48 = '9'
- i=1: route[2%5]='n'(110) + 'u'(117) + 4*2=8 => (110+117+8)%10+48 = 235%10+48 = 5+48 = '5'
- i=2: route[3%5]='a'(97) + 'b'(98) + 4*3=12 => (97+98+12)%10+48 = 207%10+48 = 7+48 = '7'
- i=3: route[4%5]='l'(108) + 'b'(98) + 4*4=16 => (108+98+16)%10+48 = 222%10+48 = 2+48 = '2'
seat = 9572
sub_401058,调用sub_400F1C
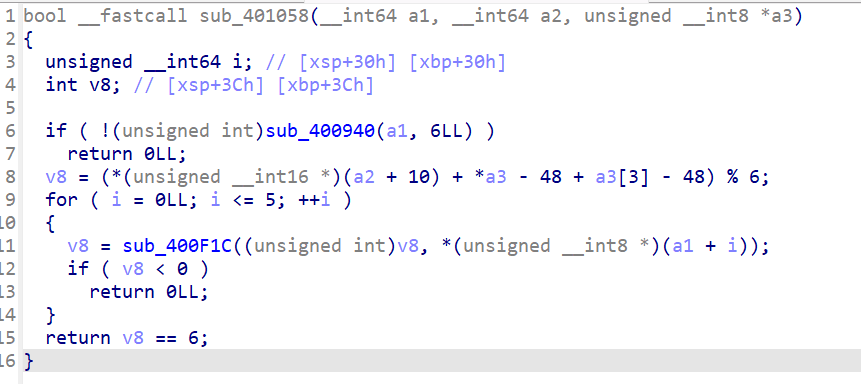
sub_400F1C反编译如下
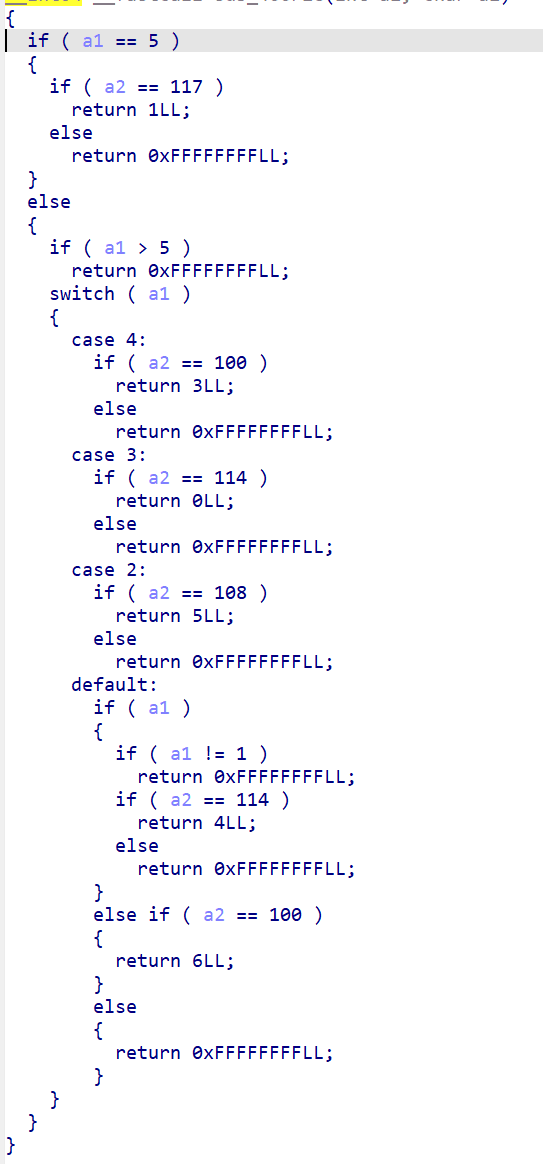
分析发现一个 7 节点的有向图,每个节点只接受一个方向字符(l/u/r/d)跳转到另一个节点:
节点0 --d--> 节点6
节点1 --r--> 节点4
节点2 --l--> 节点5
节点3 --r--> 节点0
节点4 --d--> 节点3
节点5 --u--> 节点1
起始节点由 booth 数据计算:(33 + 57 + (0x32 - 0x60)) % 6 = 44 % 6 = 2
需要在 6 步内从节点 2 到达节点 6:
2 -l-> 5 -u-> 1 -r-> 4 -d-> 3 -r-> 0 -d-> 6
path = lurdrd
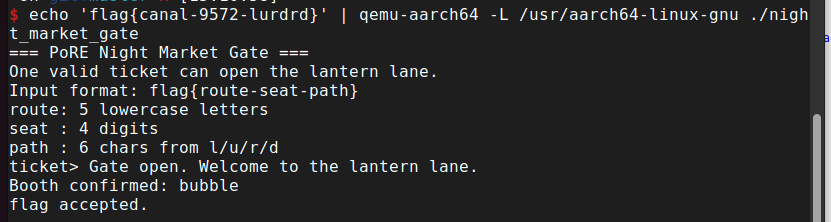
$ echo 'flag{canal-9572-lurdrd}' | qemu-aarch64 -L /usr/aarch64-linux-gnu ./night_market_gate === PoRE Night Market Gate === ... Gate open. Welcome to the lantern lane. Booth confirmed: bubble flag accepted.
- flag:
flag{canal-9572-lurdrd}
maze_game 是动态链接的 AArch64 程序,未剥离符号。程序运行后提示用 wasd 控制移动,不允许立即回头(比如往上走之后不能立刻往下走)。
用 ida分析 build_maze 函数,发现迷宫是 31x31 的,先把每行全填 '0'(墙),然后根据 .data.rel.ro 中的 ROW_SPECS 数组覆盖特定位置为路径字符。
- wasd 分别对应上/左/下/右
- 碰墙或出界就 Game over
- 不允许立即回头(例如按了 w 之后不能马上按 s)
- 到达出口输出 "Success!"
我写了 python脚本解析 ELF 的 .rodata 和 .data.rel.ro 段,提取出完整的 31x31 迷宫:
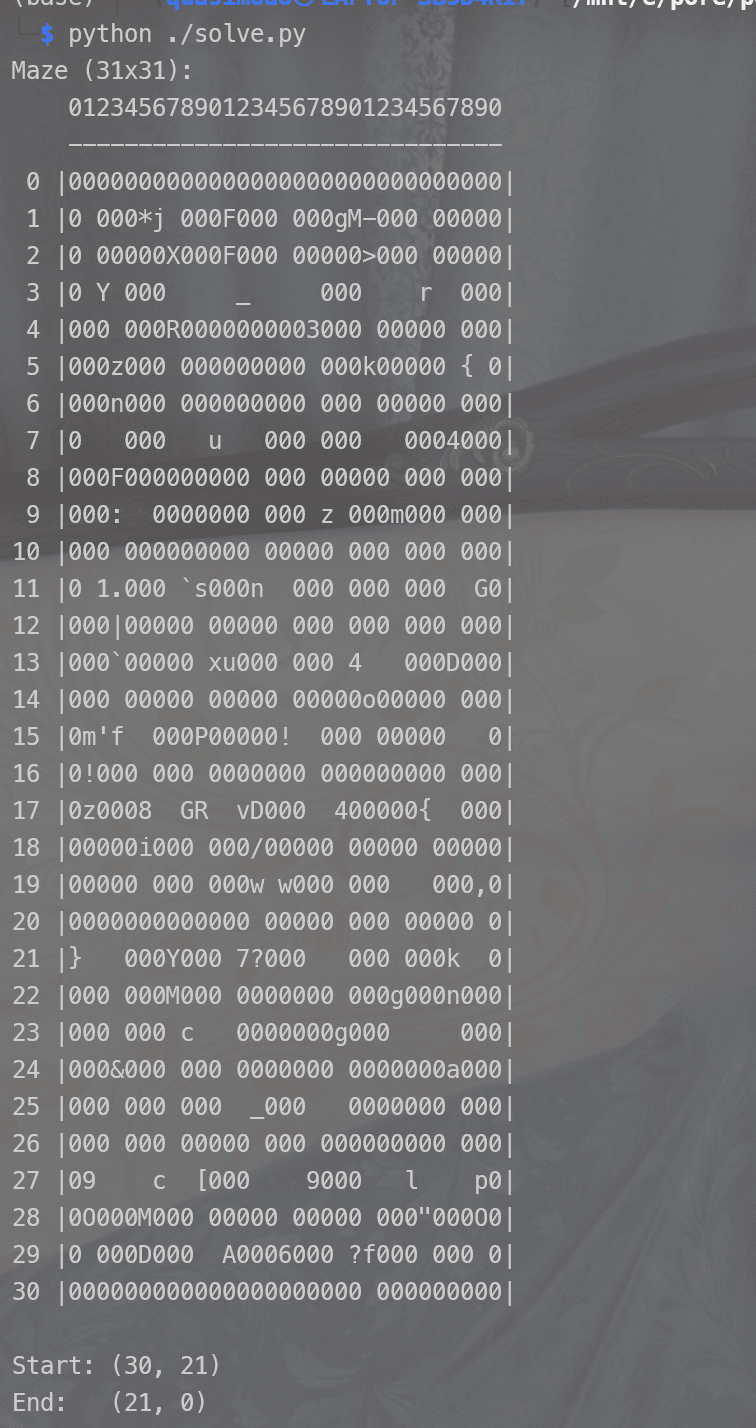
0123456789012345678901234567890 0 |0000000000000000000000000000000| 1 |0 000*j 000F000 000gM-000 00000| 2 |0 00000X000F000 00000>000 00000| 3 |0 Y 000 _ 000 r 000| 4 |000 000R0000000003000 00000 000| 5 |000z000 000000000 000k00000 { 0| 6 |000n000 000000000 000 00000 000| 7 |0 000 u 000 000 0004000| 8 |000F000000000 000 00000 000 000| 9 |000: 0000000 000 z 000m000 000| 10 |000 000000000 00000 000 000 000| 11 |0 1.000 `s000n 000 000 000 G0| 12 |000|00000 00000 000 000 000 000| 13 |000`00000 xu000 000 4 000D000| 14 |000 00000 00000 00000o00000 000| 15 |0m'f 000P00000! 000 00000 0| 16 |0!000 000 0000000 000000000 000| 17 |0z0008 GR vD000 400000{ 000| 18 |00000i000 000/00000 00000 00000| 19 |00000 000 000w w000 000 000,0| 20 |0000000000000 00000 000 00000 0| 21 |} 000Y000 7?000 000 000k 0| 22 |000 000M000 0000000 000g000n000| 23 |000 000 c 0000000g000 000| 24 |000&000 000 0000000 0000000a000| 25 |000 000 000 _000 0000000 000| 26 |000 000 00000 000 000000000 000| 27 |09 c [000 9000 l p0| 28 |0O000M000 00000 00000 000"000O0| 29 |0 000D000 A0006000 ?f000 000 0| 30 |000000000000000000000 000000000|
起点在 (30,21)(空格),终点在 (21,0)(}字符)。

用BFS 算法搜索最短路径(考虑了不允许立即回头的约束),找到 154 步的通关路径:
wwwddddddwwwwaaaawwwwddwwddwwwwwwwwwwwwwwaaaaaassssddssssssaaaawwwwaawwwwwwaaaaaaaaaassssddddddssssddssssddssddssssssssaassaaaawwaawwaaaassssaaaawwwwwwaaa
flag 由路径上遇到的非空格、非墙壁字符依次拼接而成:
| 步骤 | 位置 | 字符 |
|---|---|---|
| 1 | (29,21) | f |
| 6 | (27,24) | l |
| 12 | (24,27) | a |
| 18 | (22,23) | g |
| 25 | (17,25) | { |
| 31 | (13,27) | D |
| 37 | (7,27) | 4 |
| 43 | (3,25) | r |
| 49 | (5,21) | k |
| 55 | (9,23) | m |
| 62 | (13,20) | 4 |
| 68 | (9,18) | z |
| 74 | (4,17) | 3 |
| 80 | (3,12) | _ |
| 86 | (4,7) | R |
| 92 | (7,10) | u |
| 99 | (11,13) | n |
| 105 | (15,15) | ! |
| 111 | (17,19) | 4 |
| 117 | (23,19) | g |
| 123 | (27,17) | 9 |
| 129 | (25,13) | _ |
| 136 | (23,8) | c |
| 142 | (27,6) | c |
| 148 | (24,3) | & |
| 154 | (21,0) | } |
(这里使用了vibe coding):
#!/usr/bin/env python3 """ Maze game solver for PoRE PJ1 03-maze Extracts maze from binary, finds path from start to exit, collects flag characters. """ import struct from collections import deque def extract_maze(binary_path): """Extract the 31x31 maze from the binary.""" with open(binary_path, 'rb') as f: binary = f.read() # Parse ELF section headers e_shoff = struct.unpack_from('<Q', binary, 40)[0] e_shentsize = struct.unpack_from('<H', binary, 58)[0] e_shnum = struct.unpack_from('<H', binary, 60)[0] e_shstrndx = struct.unpack_from('<H', binary, 62)[0] shstr_hdr_off = e_shoff + e_shstrndx * e_shentsize shstr_offset = struct.unpack_from('<Q', binary, shstr_hdr_off + 24)[0] shstr_size = struct.unpack_from('<Q', binary, shstr_hdr_off + 32)[0] shstrtab = binary[shstr_offset:shstr_offset + shstr_size] sections = {} for i in range(e_shnum): off = e_shoff + i * e_shentsize sh_name = struct.unpack_from('<I', binary, off)[0] name = shstrtab[sh_name:shstrtab.index(b'\x00', sh_name)].decode() sh_addr = struct.unpack_from('<Q', binary, off + 16)[0] sh_offset = struct.unpack_from('<Q', binary, off + 24)[0] sh_size = struct.unpack_from('<Q', binary, off + 32)[0] sections[name] = (sh_addr, sh_offset, sh_size) dro_vaddr, dro_foff, dro_size = sections['.data.rel.ro'] ro_vaddr, ro_foff, ro_size = sections['.rodata'] def vaddr_to_foff(vaddr): if ro_vaddr <= vaddr < ro_vaddr + ro_size: return ro_foff + (vaddr - ro_vaddr) return None # Parse ROW_SPECS row_specs = [] for i in range(31): off = dro_foff + i * 16 ptr = struct.unpack_from('<Q', binary, off)[0] cnt = struct.unpack_from('<Q', binary, off + 8)[0] row_specs.append((ptr, cnt)) # Build maze: 31x31, default '0' (wall) maze = [['0'] * 31 for _ in range(31)] for row_idx, (ptr, cnt) in enumerate(row_specs): if cnt == 0 or ptr == 0: continue foff = vaddr_to_foff(ptr) for j in range(cnt): entry_off = foff + j * 8 col = struct.unpack_from('<I', binary, entry_off)[0] val = struct.unpack_from('<I', binary, entry_off + 4)[0] maze[row_idx][col] = chr(val) if 0x20 <= val < 0x7f else '?' return maze def solve_maze(maze, start, end): """ BFS to find shortest path from start to end. No immediate backtracking constraint is handled by tracking last direction. State: (row, col, last_move) """ rows, cols = len(maze), len(maze[0]) sr, sc = start er, ec = end # Directions: w=up, s=down, a=left, d=right moves = { 'w': (-1, 0), 's': (1, 0), 'a': (0, -1), 'd': (0, 1), } opposites = {'w': 's', 's': 'w', 'a': 'd', 'd': 'a'} # BFS: state = (row, col, last_move_char) # last_move_char = None for start queue = deque() queue.append((sr, sc, None, "")) # row, col, last_move, path_string visited = set() visited.add((sr, sc, None)) while queue: r, c, last_move, path = queue.popleft() if r == er and c == ec: return path for move_char, (dr, dc) in moves.items(): # No immediate backtracking if last_move is not None and move_char == opposites[last_move]: continue nr, nc = r + dr, c + dc if 0 <= nr < rows and 0 <= nc < cols and maze[nr][nc] != '0': state = (nr, nc, move_char) if state not in visited: visited.add(state) queue.append((nr, nc, move_char, path + move_char)) return None def collect_output(maze, start, path): """Simulate the game and collect printed characters.""" r, c = start output = "" # Starting cell ch = maze[r][c] if ch != ' ' and ch != '0': output += ch for move_char in path: if move_char == 'w': r -= 1 elif move_char == 's': r += 1 elif move_char == 'a': c -= 1 elif move_char == 'd': c += 1 ch = maze[r][c] if ch != ' ' and ch != '0': output += ch return output def main(): binary_path = '/mnt/e/pore/pore_24300240030/pj1/PJ1-Handout/03-maze/maze_game' maze = extract_maze(binary_path) # Print maze print("Maze (31x31):") print(" " + "".join(f"{i % 10}" for i in range(31))) print(" " + "-" * 31) for r in range(31): print(f"{r:2d} |{''.join(maze[r])}|") # Start: row=30, col=21; End: row=21, col=0 start = (30, 21) end = (21, 0) print(f"\nStart: {start}") print(f"End: {end}") path = solve_maze(maze, start, end) if path is None: print("No path found!") return print(f"\nPath ({len(path)} moves): {path}") output = collect_output(maze, start, path) print(f"\nCollected output (flag): {output}") # Also show step by step print("\nStep-by-step:") r, c = start ch = maze[r][c] if ch != ' ' and ch != '0': print(f" Start ({r},{c}): '{ch}'") for i, move_char in enumerate(path): if move_char == 'w': r -= 1 elif move_char == 's': r += 1 elif move_char == 'a': c -= 1 elif move_char == 'd': c += 1 ch = maze[r][c] if ch != ' ' and ch != '0': print(f" Step {i+1} ({r},{c}) move='{move_char}': '{ch}'") if __name__ == '__main__': main()
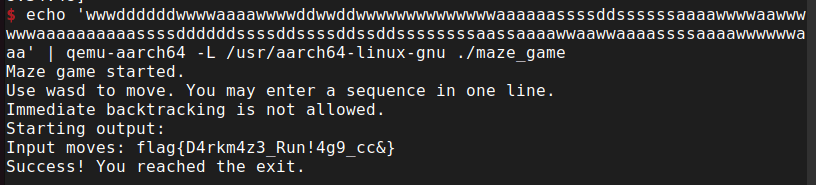
$ echo 'wwwddddddwwwwaaaawwwwddwwddwwwwwwwwwwwwwwaaaaaassssddssssssaaaawwwwaawwwwwwaaaaaaaaaassssddddddssssddssssddssddssssssssaassaaaawwaawwaaaassssaaaawwwwwwaaa' | qemu-aarch64 -L /usr/aarch64-linux-gnu ./maze_game
Maze game started.
Use wasd to move. You may enter a sequence in one line.
Immediate backtracking is not allowed.
Starting output:
Input moves: flag{D4rkm4z3_Run!4g9_cc&}
Success! You reached the exit.
- flag:
flag{D4rkm4z3_Run!4g9_cc&}
relaybox_aarch64 是一个 stripped 的静态链接 AArch64 程序,没有用 libc。也是stripped的。
查看函数列表,识别出sub_210C54是main,然后继续分析得到下面对应的函数表
| 函数名 | 地址 | 功能 |
|---|---|---|
| start | 0x210C40 | entry point,跳转到 main |
| sub_210C54 | 0x210C54 | main:输入验证 + 调用三个 phase |
| sub_210E84 | 0x210E84 | Phase 1:前 8 位验证 |
| sub_21104C | 0x21104C | Phase 2:中间 6 位验证 (TinyVM) |
| sub_2111A4 | 0x2111A4 | Phase 3:后 4 位验证 |
| sub_211220 | 0x211220 | Flag 解密输出 |
main的反编译如下:
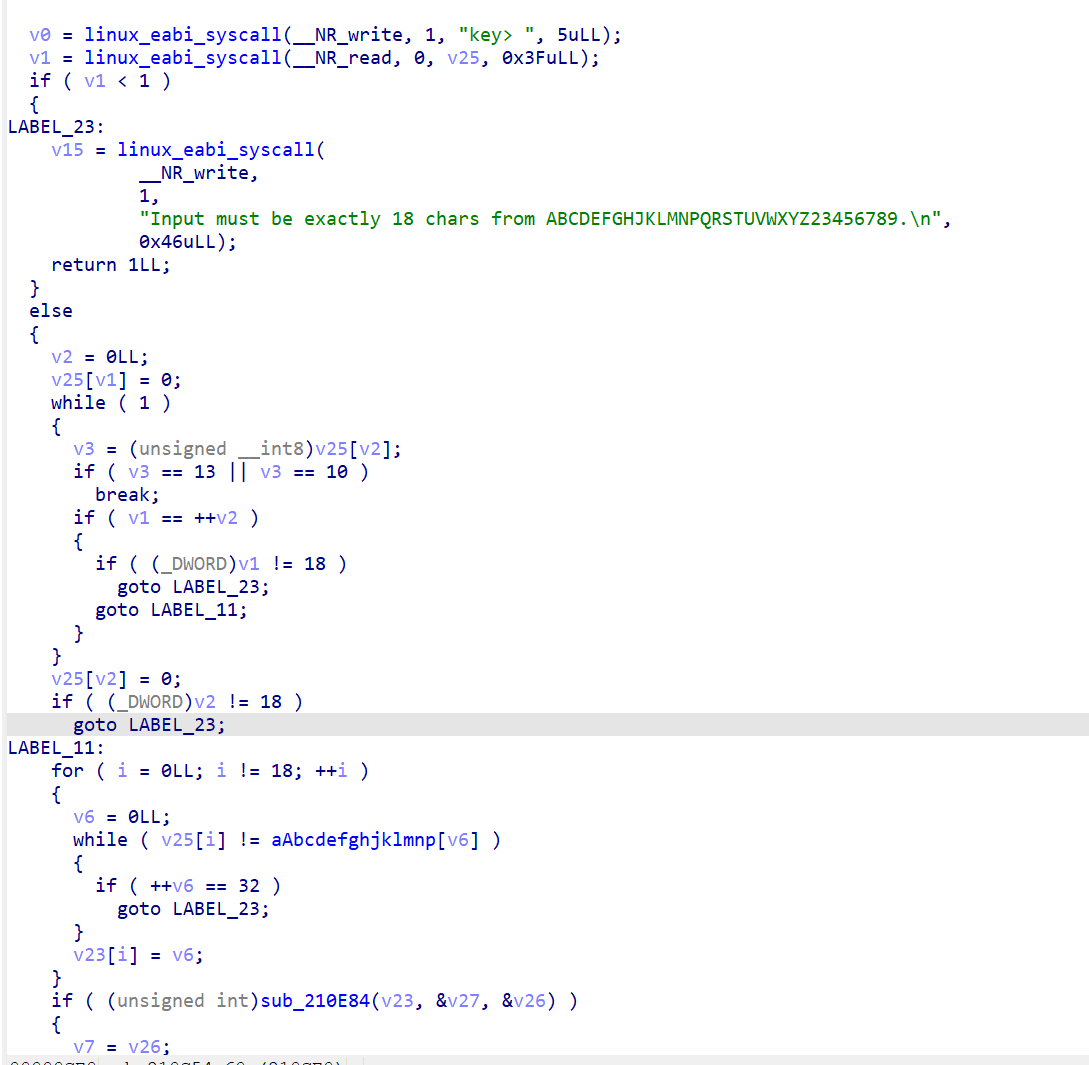

直接用 svc #0 系统调用做 I/O,程序要求输入 18 个字符,字符集为 ABCDEFGHJKLMNPQRSTUVWXYZ23456789(32 个字符,每个字符恰好编码 5 bit),分 3 个 phase 验证。
分析验证函数0x210E84,
 发现 Phase 1 有三重约束:
发现 Phase 1 有三重约束:
- 状态机:11 个状态,32 种输入。将 8 个字符依次送入状态转移表,要求最终状态 == 3。
- 滚动哈希:12-bit 值,每步做左旋 3 位、XOR 查表值、加上 state*0x31+0x31,最终要求 == 0x772。
- 打包值校验:8 个 5-bit 索引打包成 40-bit 值,左移 13 位,经异或和 64 位乘法校验:
状态转移表数据 (0x200264)

packed = (c[0] | c[1]<<5 | ... | c[7]<<35) << 13
打包值校验的关键常量:
(packed ^ 0x1add1fd70ccb2000) * 0x9e3779b185ebca87 == 0x84d608987ce82000
第三个约束最强,可以直接用 64 位模逆运算解出唯一解,然后验证前两个约束也满足。
python解题脚本
# 64位模逆求解 mod = 1 << 64 target = 0x84D608987CE82000 mult = 0x9E3779B185EBCA87 xor_val = 0x1ADD1FD70CCB2000 # 求乘法逆元 inv = pow(mult, -1, mod) packed = ((target * inv) % mod) ^ xor_val # 去掉左移 13 位 packed >>= 13 charset = "ABCDEFGHJKLMNPQRSTUVWXYZ23456789" result = '' for i in range(8): idx = (packed >> (i*5)) & 0x1f result += charset[idx] print(result) # Q7M4KX9T
结果:Q7M4KX9T
0x21104C

Phase 2 实现了一个自定义虚拟机:4 个 32-bit 寄存器,22 条指令,8 种 opcode(加载立即数、LUT 查表更新、加法旋转、异或旋转、交换等)。
同时 6 个字符通过 NEON 指令打包为 30-bit 值,经 64 位乘法校验:
((packed ^ 0x5a92d4e3) * 0x6ef3630bd7950e00) == 0x9fb6cf262210ce00
乘法器含 2^9 因子,除去后求模逆,直接解出 30-bit 打包值,类似 Phase 1 的方法解出 6 个 5-bit 索引,再通过 VM 执行验证寄存器最终状态。
结果:C8R2V6
0x2111A4
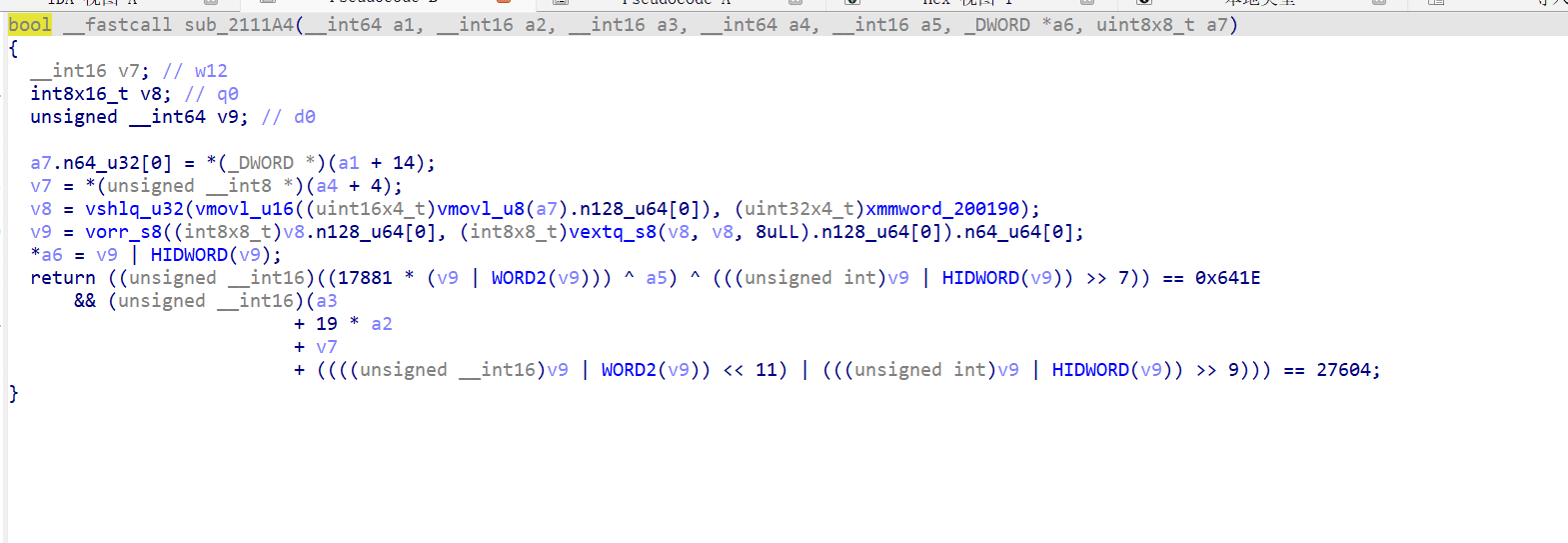
4 个字符打包为 20-bit 值,通过两个 16-bit 算术约束验证。搜索空间只有 32^4 ≈ 100 万,暴力枚举即可。
charset = "ABCDEFGHJKLMNPQRSTUVWXYZ23456789" for a in range(32): for b in range(32): for c in range(32): for d in range(32): packed = a | (b<<5) | (c<<10) | (d<<15) # 检查两个约束... if check1(packed) and check2(packed): print(charset[a]+charset[b]+charset[c]+charset[d])
结果:NH3P
Flag 解密
三个 phase 全部通过后,程序用各 phase 的输出构造密钥流,对 0x200c1c 处的 33 字节数据做 XOR 解密得到 flag。

$ echo 'Q7M4KX9TC8R2V6NH3P' | qemu-aarch64 -L /usr/aarch64-linux-gnu ./relaybox_aarch64 key> flag{pore26_relaybox_fsm_vm_bits}
- flag:
flag{pore26_relaybox_fsm_vm_bits}
relaylog 是一个 stripped 静态链接 AArch64 程序,读取固定格式的日志文件 relay_note.bin
先尝试运行一下

发现有stage1,然后打开ida开始逆向,发现是stripped + 静态链接,函数很tm多(1000+),但实际只需关注少数几个
直接搜字符串stage看看情况
找到 "[stage 1]", "[stage 2]", "[stage 3]", "all stages cleared" 等字符串
双击,然后按 X 查看引用,筛选下来 实际只需要关注 1 个核心函数,名字是 sub_400520
这个程序的 stage 1/2/3 不是独立的子函数,三个阶段的全部逻辑都写在 sub_400520 这一个大函数里(约 200 行伪代码),通过嵌套 if-else 实现。
- entry (0x400A40)
→ sub_400D70 (相当于 __libc_start_main)
→ sub_400520(真正的 main,包含文件读取 + stage 1/2/3 全部逻辑)
打开010editor查看 relay_note.bin 十六进制内容,日志文件共 96 字节,由 24 字节的 Header 和 6 条 12 字节的 Record 组成。如下
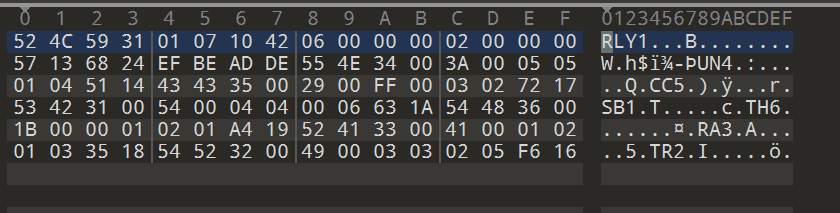
Header 结构 (24 字节):
| 偏移 | 大小 | 字段名 | 含义 |
|---|---|---|---|
| 0x00 | 4 | magic | 魔数 |
| 0x04 | 1 | version | 版本号 |
| 0x05 | 1 | field_05 | 固定字段 |
| 0x06 | 2 | type_tag | 类型标记 |
| 0x08 | 4 | record_count | 记录条数 |
| 0x0C | 4 | first_idx | 链表起始索引 |
| 0x10 | 4 | seed | 累加初始值 |
| 0x14 | 4 | checksum | 校验和 |
Record 结构 (每条 12 字节):
| 偏移 | 大小 | 字段名 | 含义 |
|---|---|---|---|
| 0x00 | 1 | tag[0] | 标签字符1(stage 2 使用) |
| 0x01 | 1 | tag[1] | 标签字符2(stage 3 使用) |
| 0x04 | 2 | priority | 优先级(小端) |
| 0x06 | 1 | next_idx | 链表下一条索引 |
| 0x07 | 1 | slot_idx | 槽位索引 |
| 0x08 | 1 | mode | 模式(stage 3 switch 分支选择) |
大概在函数内约偏移 +0x70 处

需要满足的条件:
- magic ==
RLY0(0x30594C52) - version == 0x02
- type_tag == 0x4254
- checksum == 基于前 20 字节计算的值
损坏字段:
- magic 最后一字节 0x31 应为 0x30("RLY1" → "RLY0")
- version 0x01 应为 0x02
- type_tag 0x4210 应为 0x4254
checksum 计算方法:
int k = 0x9d, sum = 0x31415926; for (int i = 0; i < 20; i++) { sum += data[i] + k; k += 3; } checksum = sum + 0x45d9f3b;
按照这样的分析修改前面的relay_note.bin文件,修复 header 字段后重新计算 checksum = 0x359F09A3,替换原来的 0xDEADBEEF。
- flag:
flag{little_endian_header}
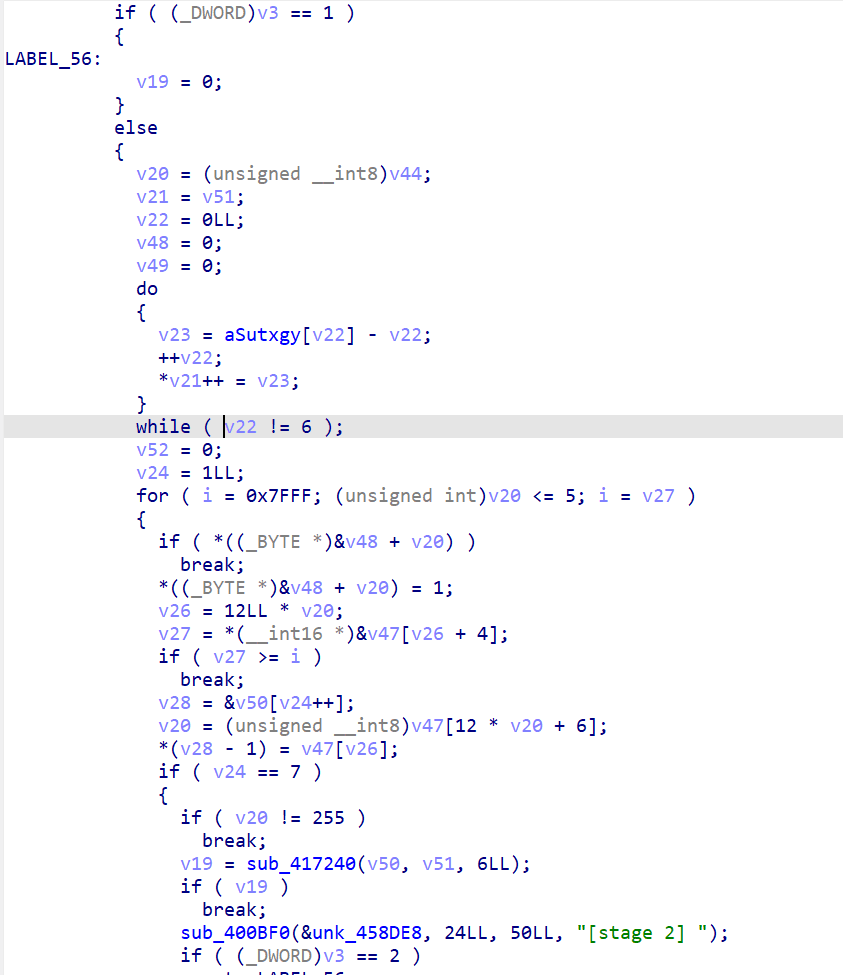
v20 = (unsigned __int8)v44; // v20 = cur_idx = first_idx = 2 // 0x400794: 初始化遍历计数器 v24 = 1LL; // 0x4007B8: 主循环 — for (i = 0x7FFF; v20 <= 5; i = v27) // i 就是 prev_priority,初始极大值 0x7FFF for ( i = 0x7FFF; (unsigned int)v20 <= 5; i = v27 ) { if ( *((_BYTE *)&v48 + v20) ) // 0x4007BC: visited[v20] 已访问? break; *((_BYTE *)&v48 + v20) = 1; // 0x4007CC: 标记已访问 v26 = 12LL * v20; // 每条 record 12 字节 v27 = *(__int16 *)&v47[v26 + 4]; // 0x4007D4: 读取 priority (record 偏移+4) if ( v27 >= i ) // 0x4007DC: priority 必须严格递减 break; v28 = (char *)&v50 + v24++; // 0x4007E0: 输出位置 v20 = (unsigned __int8)v47[12 * v20 + 6]; // 0x4007EC: 读取 next_idx (偏移+6) *(v28 - 1) = v47[v26]; // 0x4007F0: 收集 tag[0] (偏移+0) if ( v24 == 7 ) // 0x4007F8: 已收集 6 条 { if ( v20 == 255 ) // 0x400834: 最后一条 next_idx == 0xFF? { v19 = sub_417240(&v50, &v50+8, 6); // 0x400848: strcmp("STRUCT") if ( !v19 ) sub_400BF0(..., "[stage 2] "); // 0x400868: Stage 2 通过! } break; } } // 失败: 落到外层,最终跳到 sub_4082D0("[stage 2] relay order is broken")
从 first_idx=2 开始,沿 next_idx 链式遍历 6 条记录。要求:
- 每条记录只访问一次
- priority 严格递减
- 最后一条 next_idx == 0xFF(终止)
- 收集每条记录的 tag[0] 组成字符串 = "STRUCT"
6 条记录的 priority 分别是:58, 41, 84, 27, 65, 73
按降序排列:rec2(S,84) → rec5(T,73) → rec4(R,65) → rec0(U,58) → rec1(C,41) → rec3(T,27)
tag[0] 拼接:S-T-R-U-C-T = STRUCT
修复各记录的 next_idx:rec2→5, rec5→4, rec4→0, rec0→1, rec1→3, rec3→0xFF
- flag:
flag{struct_chain_fixed}
分析stage3反编译
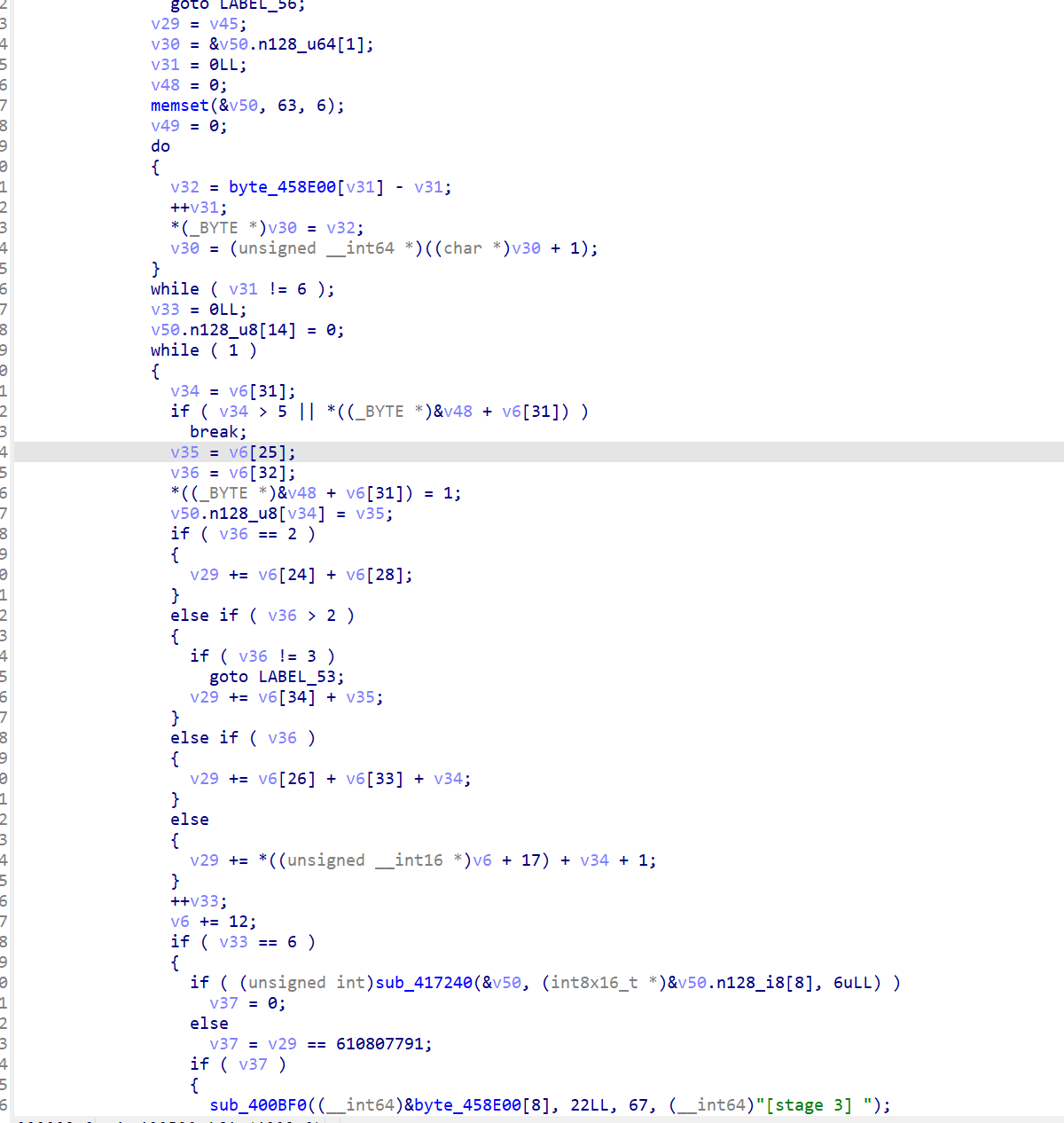
// 0x400894: 初始化 6 个输出槽位为 '?' (63 = 0x3F) v29 = v45; // v29 = seed 初始值 (610800471 = 0x24681357) memset(&v50, 63, 6); // v50 = output_slots,6 字节全填 '?' // 0x4008C4: 主循环 — 按文件顺序遍历 6 条 record while ( 1 ) { v34 = v6[31]; // 0x4008C4: slot_idx (v6 指向当前 record,偏移 31=24+7) if ( v34 > 5 // 0x4008D4: slot_idx 越界? || *((_BYTE *)&v48 + v6[31]) ) // visited[slot] 已占用? break; v35 = v6[25]; // 0x4008E0: tag[1] (偏移 25=24+1) v36 = v6[32]; // 0x4008E4: mode (偏移 32=24+8) *((_BYTE *)&v48 + v6[31]) = 1; // 标记已占用 v50.n128_u8[v34] = v35; // 0x4008EC: output_slot[v34] = tag[1] // switch(v36) — mode 决定累加方式 if ( v36 == 2 ) // case 2 (0x4009A0): v29 += v6[24] + v6[28]; // seed += tag[0] + field_9 else if ( v36 > 2 ) { if ( v36 != 3 ) goto LABEL_53; // 非法 mode v29 += v6[34] + v35; // case 3 (0x40097C): seed += field10_hi + tag[1] } else if ( v36 ) // case 1 (0x400910): v29 += v6[26] + v6[33] + v34; // seed += field_xx + v34 else // case 0 (0x4009B0): v29 += *((unsigned __int16 *)v6 + 17) + v34 + 1; // seed += field10 + slot + 1 ++v33; // 0x400914: 计数器++ v6 += 12; // 0x400918: 移到下一条 record if ( v33 == 6 ) // 0x400920: 6 条遍历完 { // 最终校验 if ( sub_417240(&v50, &v50+8, 6) == 0 // 0x40092C: strcmp("BRANCH") && v29 == 610807791 ) // 0x40093C: v29 == 0x24682FEF { sub_400BF0(..., "[stage 3] "); // 0x4009D0: 输出 flag3 sub_4082D0("all stages cleared"); } } }
按文件顺序遍历 6 条记录,每条记录的 slot_idx 指定 tag[1] 放入 result 数组的哪个位置,最终 result = "BRANCH"。同时根据 mode 字段选择 switch 分支累加计算,最终累加值需等于 0x24682FEF。
| rec | tag[1] | 应放入 slot |
|---|---|---|
| 0 | N | 3 |
| 1 | C | 4 |
| 2 | B | 0 |
| 3 | H | 5 |
| 4 | A | 2(不变) |
| 5 | R | 1 |
修复 slot_idx 后,mode 和辅助字段恰好无需修改,累加值自然满足。
- flag:
flag{switch_slot_done}
import struct with open('relay_note.bin', 'rb') as f: data = bytearray(f.read()) # Stage 1: 修复 header data[3] = 0x30 # magic: RLY1 -> RLY0 data[4] = 0x02 # version data[6] = 0x54 # type_tag low data[7] = 0x42 # type_tag high # 重新计算 checksum k, s = 0x9d, 0x31415926 for i in range(20): s = (s + data[i] + k) & 0xffffffff k += 3 checksum = (s + 0x45d9f3b) & 0xffffffff struct.pack_into('<I', data, 0x14, checksum) # Stage 2: 修复 next_idx (offset 0x06 in each 12-byte record, header=24 bytes) # rec order: 2->5->4->0->1->3(end) data[24 + 2*12 + 6] = 5 # rec2.next = 5 data[24 + 5*12 + 6] = 4 # rec5.next = 4 data[24 + 4*12 + 6] = 0 # rec4.next = 0 data[24 + 0*12 + 6] = 1 # rec0.next = 1 data[24 + 1*12 + 6] = 3 # rec1.next = 3 data[24 + 3*12 + 6] = 0xFF # rec3.next = 0xFF (end) # Stage 3: 修复 slot_idx (offset 0x07 in each record) data[24 + 0*12 + 7] = 3 # rec0 tag[1]='N' -> slot 3 data[24 + 1*12 + 7] = 4 # rec1 tag[1]='C' -> slot 4 data[24 + 2*12 + 7] = 0 # rec2 tag[1]='B' -> slot 0 data[24 + 3*12 + 7] = 5 # rec3 tag[1]='H' -> slot 5 data[24 + 4*12 + 7] = 2 # rec4 tag[1]='A' -> slot 2 data[24 + 5*12 + 7] = 1 # rec5 tag[1]='R' -> slot 1 with open('relay_note_fixed.bin', 'wb') as f: f.write(data)
用 Python 脚本修复后的文件运行:
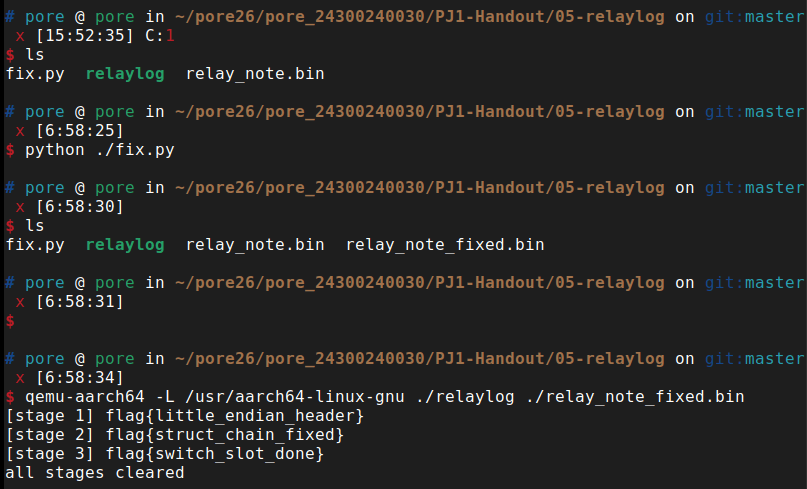
$ qemu-aarch64 -L /usr/aarch64-linux-gnu ./relaylog ./relay_note_fixed.bin
[stage 1] flag{little_endian_header}
[stage 2] flag{struct_chain_fixed}
[stage 3] flag{switch_slot_done}
all stages cleared
- 修复后的文件:
relay_note_fixed.bin - 三段 flag 如上所示
- [stage 1] flag{little_endian_header}
[stage 2] flag{struct_chain_fixed}
[stage 3] flag{switch_slot_done}
打开magic文件,发现magic 是一个未剥离符号的动态链接 AArch64 程序(C++ 编写),功能是加密 PNG 文件。需要逆向加密逻辑,找到 seed,编写解密程序恢复 flag.png.magic 为原始图片。
用 ida分析主要函数main:
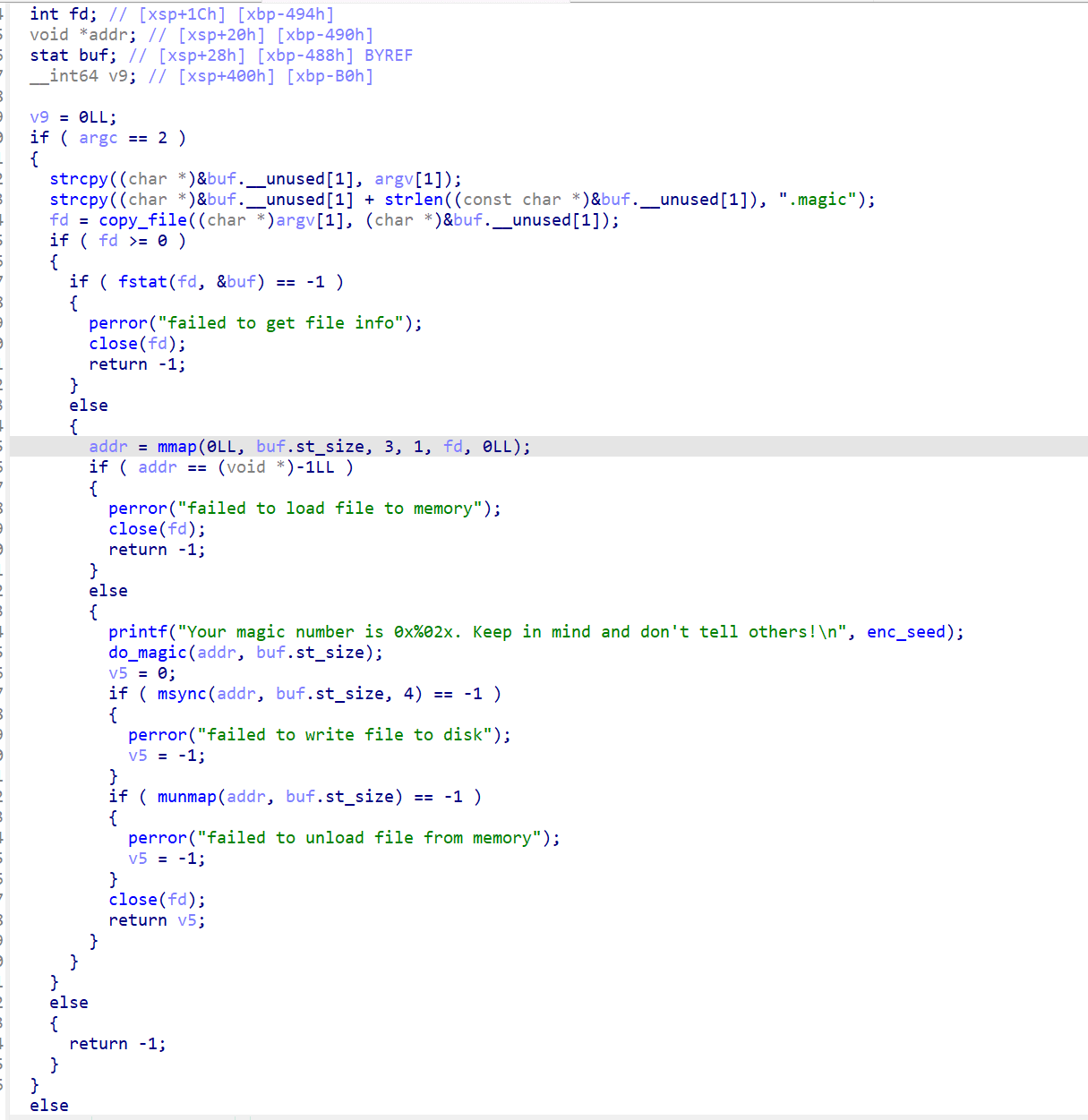
有下面这些重要函数:
-
init_ops():程序启动时通过全局初始化调用。生成enc_seed = rand() % 0xff(0~254),初始化自定义 PRNG(orange_rand),然后随机将 8 个操作函数分配到调度表中。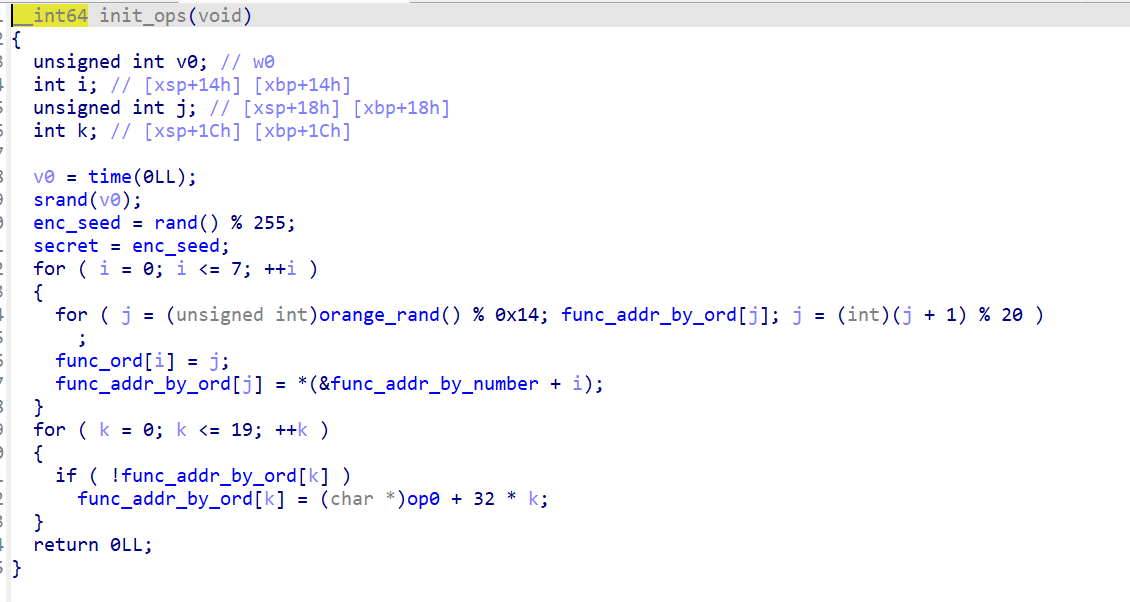
-
orange_rand():自定义 LCG,模数为 10^9+7:
-
do_magic():以 4 字节(uint32 小端序)为单位处理数据。对每个块:调用 orange_rand() 获取随机数,用r & 7选择操作函数,应用操作,然后与前一个加密块 XOR(CBC 链接,第一个块跳过)。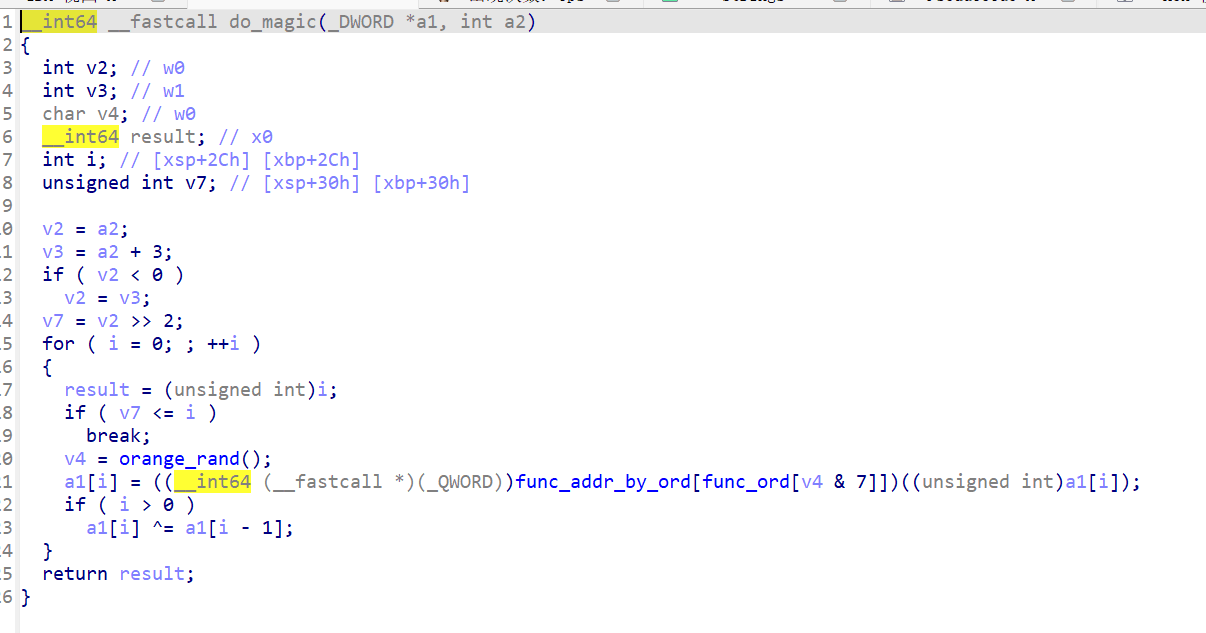
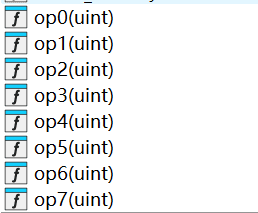
太多了就不逐一截图展示反汇编了,总结如下
| 操作 | 功能 | 逆操作 |
|---|---|---|
| op0 | XOR 0x12345678 | 自逆(再 XOR 一次) |
| op1 | 交换相邻字节 | 自逆 |
| op2 | 加 0x87654321 | 减 0x87654321 |
| op3 | 高低16位交换 | 自逆 |
| op4 | 交换半字节 | 自逆 |
| op5 | 加 0xEDCBA988 | 减 0xEDCBA988 |
| op6 | XOR 0x67616C66 ("flag") | 自逆 |
| op7 | 加 0xE9 | 减 0xE9 |
- 逆 CBC:从最后一个块向前,
blocks[i] ^= blocks[i-1] - 逆操作:对每个块应用对应操作的逆函数
seed 范围只有 0~254,我暴力枚举所有可能的 seed,对每个 seed 尝试解密,检查输出是否以有效的 PNG 签名(\x89PNG\r\n\x1a\n)和 IHDR 块头(长度=13, 类型="IHDR")开头。
只有 seed = 0x4e (78) 同时满足 PNG 签名和 IHDR 校验。
def decrypt(data, seed): # 初始化 PRNG 和操作映射 secret = seed func_ord = assign_ops(seed) # 模拟 init_ops blocks = [struct.unpack('<I', data[i:i+4])[0] for i in range(0, len(data), 4)] # 记录每个块使用的操作 ops_used = [] secret = seed for i in range(len(blocks)): r = orange_rand() ops_used.append(func_ord[r & 7]) # 逆 CBC(从后往前) for i in range(len(blocks)-1, 0, -1): blocks[i] ^= blocks[i-1] # 逆操作 for i in range(len(blocks)): blocks[i] = inverse_op(ops_used[i], blocks[i]) return b''.join(struct.pack('<I', b) for b in blocks)
#!/usr/bin/env python3 """ Decrypt flag.png.magic encrypted by the 'magic' program. Encryption algorithm analysis: 1. init_ops() initializes a PRNG (orange_rand) with enc_seed, then shuffles 8 operation functions (op0-op7) into a 20-slot table using the PRNG. 2. do_magic() processes data as uint32 blocks: - For each block i: call orange_rand(), select op via (rand & 7) -> func_ord -> func_addr_by_ord - Apply the selected op to block[i] - If i > 0: block[i] ^= block[i-1] (CBC-like chaining) To decrypt: reverse the process (undo CBC XOR first, then invert each op). """ import struct import sys import os MASK32 = 0xFFFFFFFF # ---- The 8 encryption operations and their inverses ---- def op0(x): # XOR with constant return (x ^ 0x12345678) & MASK32 def op0_inv(x): # XOR is self-inverse return (x ^ 0x12345678) & MASK32 def op1(x): # swap bytes: (x & 0x00FF00FF) << 8 | (x & 0xFF00FF00) >> 8 return (((x & 0x00FF00FF) << 8) | ((x & 0xFF00FF00) >> 8)) & MASK32 def op1_inv(x): # self-inverse (same swap undoes itself) return op1(x) def op2(x): # add constant return (x + 0x87654321) & MASK32 def op2_inv(x): # subtract constant return (x - 0x87654321) & MASK32 def op3(x): # rotate 16 bits: (x << 16) | (x >> 16) return (((x << 16) | (x >> 16)) & MASK32) def op3_inv(x): # self-inverse (rotate 16 again) return op3(x) def op4(x): # swap nibbles: (x & 0xF0F0F0F0) >> 4 | (x & 0x0F0F0F0F) << 4 return (((x & 0xF0F0F0F0) >> 4) | ((x & 0x0F0F0F0F) << 4)) & MASK32 def op4_inv(x): # self-inverse return op4(x) def op5(x): # add constant (note: 0xedcba988 is negative in 2's complement: -0x12345678) return (x + 0xEDCBA988) & MASK32 def op5_inv(x): return (x - 0xEDCBA988) & MASK32 def op6(x): # XOR with "flag" in little-endian: 0x67616c66 return (x ^ 0x67616C66) & MASK32 def op6_inv(x): # self-inverse return (x ^ 0x67616C66) & MASK32 def op7(x): # add 0xe9 return (x + 0xE9) & MASK32 def op7_inv(x): return (x - 0xE9) & MASK32 ops_enc = [op0, op1, op2, op3, op4, op5, op6, op7] ops_dec = [op0_inv, op1_inv, op2_inv, op3_inv, op4_inv, op5_inv, op6_inv, op7_inv] # ---- PRNG: orange_rand ---- class OrangeRand: def __init__(self, seed): self.secret = seed def rand(self): val = ((self.secret ^ 0x3B800001) + 0x98D8BD) & MASK32 # Multiply - need 64-bit intermediate val = (val * 0x98D8BF) & 0xFFFFFFFFFFFFFFFF # secret = val + (val / 0x3B9ACA07) * (-0x3B9ACA07) # This is: secret = val % 0x3B9ACA07 (unsigned) # But in C it's: (int)val + (int)(val / 0x3B9ACA07) * -0x3B9ACA07 # With unsigned 64-bit division then truncation to 32-bit quotient = val // 0x3B9ACA07 # unsigned division of 64-bit value self.secret = (int(val) + int(quotient) * (-0x3B9ACA07)) & MASK32 # Convert to signed for return return self.secret def simulate_init_ops(enc_seed): """ Simulate init_ops() to determine func_ord and func_addr_by_ord mapping. Returns (func_ord, func_number_by_ord, final_prng_state). func_ord[i] gives the ordinal slot for op_i. func_addr_by_ord[slot] gives which op function is at that slot. """ rng = OrangeRand(enc_seed) func_addr_by_ord = [None] * 20 # None means empty, will be filled with op index func_ord = [0] * 8 for i in range(8): slot = rng.rand() % 20 while func_addr_by_ord[slot] is not None: slot = (slot + 1) % 20 func_ord[i] = slot func_addr_by_ord[slot] = i # op_i is at this slot # Fill remaining empty slots with "default" ops # In the binary: op0 + local_4 * 0x20 # op0 is at 0xd98, each op is 0x20 apart... but op functions are at: # op0=0xd98, op1=0xdb8 (diff=0x20), op2=0xdf4 (diff=0x3c), ... # Wait, the fill logic is: *(func_addr_by_ord + local_4 * 8) = op0 + local_4 * 0x20 # So the address stored is op0_addr + slot_index * 0x20 # We need to figure out which op function this corresponds to. # op0=0xd98, op1=0xdb8, op2=0xdf4, op3=0xe14, op4=0xe50, op5=0xe8c, op6=0xeac, op7=0xf30 op_addrs = [0xd98, 0xdb8, 0xdf4, 0xe14, 0xe50, 0xe8c, 0xeac, 0xf30] for slot in range(20): if func_addr_by_ord[slot] is None: # Address would be op0_addr + slot * 0x20 = 0xd98 + slot * 0x20 fill_addr = 0xd98 + slot * 0x20 # Find which op this matches (if any) if fill_addr in op_addrs: func_addr_by_ord[slot] = op_addrs.index(fill_addr) else: # Points to some other code - for slots that are actually used, # this matters. But in do_magic, we only access via func_ord[rand & 7], # and func_ord only has 8 entries (the valid ones). # Still, let's record it as a special value func_addr_by_ord[slot] = -1 # invalid/unused return func_ord, func_addr_by_ord, rng def do_magic_encrypt(data_bytes, enc_seed): """Simulate encryption to verify our understanding.""" func_ord, func_addr_by_ord, rng = simulate_init_ops(enc_seed) n = len(data_bytes) num_blocks = n // 4 blocks = list(struct.unpack(f'<{num_blocks}I', data_bytes[:num_blocks*4])) for i in range(num_blocks): r = rng.rand() op_ord = func_ord[r & 7] op_idx = func_addr_by_ord[op_ord] blocks[i] = ops_enc[op_idx](blocks[i]) if i > 0: blocks[i] = (blocks[i] ^ blocks[i-1]) & MASK32 result = struct.pack(f'<{num_blocks}I', *blocks) if n % 4 != 0: result += data_bytes[num_blocks*4:] return result def do_magic_decrypt(data_bytes, enc_seed): """Decrypt data encrypted by do_magic.""" func_ord, func_addr_by_ord, rng = simulate_init_ops(enc_seed) n = len(data_bytes) num_blocks = n // 4 blocks = list(struct.unpack(f'<{num_blocks}I', data_bytes[:num_blocks*4])) # We need to know which op is applied to each block, so generate all rand values first rand_vals = [] for i in range(num_blocks): rand_vals.append(rng.rand()) # Reverse: undo CBC XOR from last to first, then invert op for i in range(num_blocks - 1, -1, -1): # Undo CBC XOR if i > 0: blocks[i] = (blocks[i] ^ blocks[i-1]) & MASK32 # Undo the operation r = rand_vals[i] op_ord = func_ord[r & 7] op_idx = func_addr_by_ord[op_ord] blocks[i] = ops_dec[op_idx](blocks[i]) result = struct.pack(f'<{num_blocks}I', *blocks) if n % 4 != 0: result += data_bytes[num_blocks*4:] return result def check_png_header(data): """Check if data starts with PNG magic bytes.""" return data[:8] == b'\x89PNG\r\n\x1a\n' def check_png_with_ihdr(data): """Check if data starts with PNG magic + valid IHDR chunk.""" if len(data) < 16: return False if data[:8] != b'\x89PNG\r\n\x1a\n': return False # Check IHDR chunk: length should be 13, type should be 'IHDR' ihdr_len = struct.unpack('>I', data[8:12])[0] chunk_type = data[12:16] return ihdr_len == 13 and chunk_type == b'IHDR' def try_decrypt_first_16(encrypted_data, enc_seed): """Try decrypting first 16 bytes (4 blocks) to check PNG header + IHDR.""" func_ord, func_addr_by_ord, rng = simulate_init_ops(enc_seed) blocks = list(struct.unpack('<4I', encrypted_data[:16])) rand_vals = [rng.rand() for _ in range(4)] # Undo CBC XOR from last to first for i in range(3, 0, -1): blocks[i] = (blocks[i] ^ blocks[i-1]) & MASK32 # Invert each op for i in range(4): r = rand_vals[i] op_ord = func_ord[r & 7] op_idx = func_addr_by_ord[op_ord] if op_idx < 0: return None blocks[i] = ops_dec[op_idx](blocks[i]) result = struct.pack('<4I', *blocks) return result def main(): encrypted_file = '/mnt/e/pore/pore_24300240030/pj1/PJ1-Handout/06-HiddenPNG/flag.png.magic' output_file = '/mnt/e/pore/pore_24300240030/pj1/pj1_ccwork/06-hidden_png/flag.png' with open(encrypted_file, 'rb') as f: encrypted_data = f.read() print(f"Encrypted file size: {len(encrypted_data)} bytes") print(f"Encrypted header (hex): {encrypted_data[:16].hex()}") print() # Brute-force enc_seed (0 to 254, since enc_seed = rand() % 0xff) # We need to check not just PNG signature but also valid IHDR chunk print("Brute-forcing enc_seed (0-254)...") found_seed = None for seed in range(255): header = try_decrypt_first_16(encrypted_data, seed) if header is not None and check_png_with_ihdr(header): print(f" Found valid seed: 0x{seed:02x} ({seed})") found_seed = seed break if found_seed is None: print("Failed to find seed. Exiting.") sys.exit(1) print(f"\nDecrypting with seed = 0x{found_seed:02x} ({found_seed})...") decrypted_data = do_magic_decrypt(encrypted_data, found_seed) print(f"Decrypted header (hex): {decrypted_data[:16].hex()}") print(f"PNG signature valid: {check_png_header(decrypted_data)}") with open(output_file, 'wb') as f: f.write(decrypted_data) print(f"\nDecrypted file saved to: {output_file}") print(f"File size: {len(decrypted_data)} bytes") if __name__ == '__main__': main()
解密后得到一张 PNG 图片,图片上叠加显示了 flag 文字。
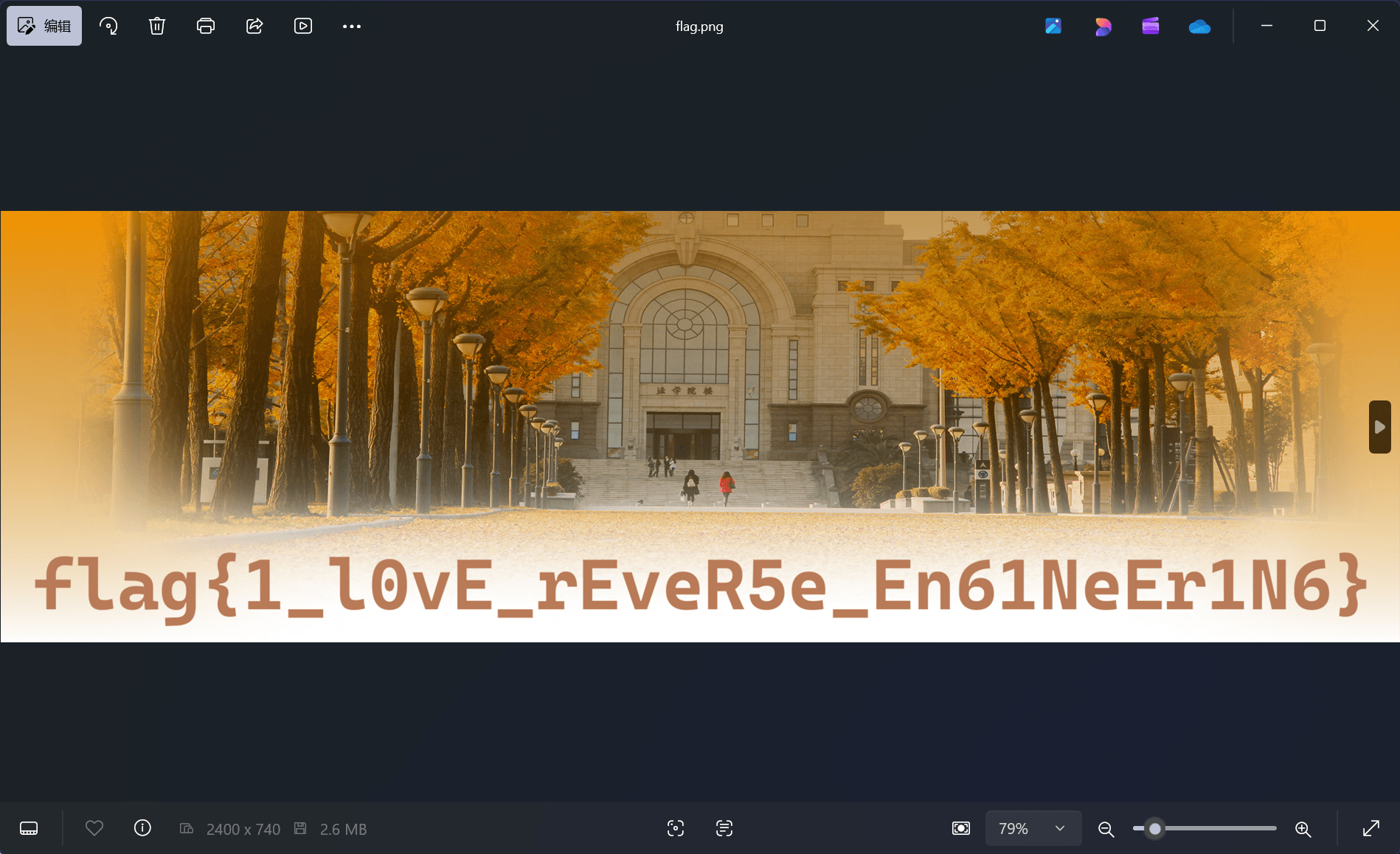
- flag:
flag{1_l0vE_rEveR5e_En61NeEr1N6} - seed =
0x4e (78)
legacy_vault 是一个 stripped 静态链接 AArch64 程序。ida打开显示只有九个函数,逐一分析可以得到大概的函数情况:
| IDA 名称 | 地址 | 大小 | 功能 |
|---|---|---|---|
| sub_4000E8 | 0x4000E8 | 0x8 | syscall read(参数通过寄存器传入) |
| sub_4000F0 | 0x4000F0 | 0x8 | syscall write |
| sub_4000F8 | 0x4000F8 | 0x24 | AES AddRoundKey(input XOR key) |
| sub_40011C | 0x40011C | 0x28 | AES SubBytes(S-box 查表) |
| sub_400144 | 0x400144 | 0xA8 | AES ShiftRows(行移位) |
| sub_4001EC | 0x4001EC | 0x88 | ChaCha20 QuarterRound |
| sub_400274 | 0x400274 | 0x28 | 输出字符串(strlen + write) |
| sub_40029C | 0x40029C | 0x758 | 核心函数:输入 + 全部加密链 + 比较 |
| start | 0x4009F4 | 0x18 | entry point |
分析核心函数 sub_40029C
前面就是一些输入提示和输入、预处理等信息
然后就是进入到一个AES-128的诱饵算法,范围约大是0x400334 ~ 0x40053C,反编译如下:
for ( i = 0LL; i != 16; ++i ) { if ( v3 ) v8 = v132[i % v3]; else v8 = 17 * i; v133[i] = v8 ^ byte_400B04[i]; } for ( j = 0LL; j != 16; ++j ) *((_BYTE *)v134 + j) = byte_400B14[j]; v10 = &v135; v11 = 0; do { for ( k = 0LL; k != 4; ++k ) *(&v128 + k) = v10[k - 4]; if ( (j & 0xF) == 0 ) { v13 = v129; v129 = byte_400B2E[v130]; LOBYTE(v13) = byte_400B2E[v13]; v130 = byte_400B2E[v131]; v131 = byte_400B2E[v128]; v14 = byte_400B24[v11]; v11 = (unsigned __int8)(v11 + 1); v128 = v13 ^ v14; } v15 = v10; for ( m = 0LL; m != 4; ++m ) { v17 = *(&v128 + m); *v15 = *(v15 - 16) ^ v17; ++v15; } j += 4LL; v10 += 4; } while ( j != 176 ); v18 = sub_4000F8(v133, v134, 176LL, byte_400B2E); do { v19 = (_BYTE *)sub_40011C(v18); v20 = sub_400144(v19); v25 = v20; do { v26 = *v25; v27 = v25[1]; v28 = v25[2]; v29 = v25[3]; v30 = 2 * ((v26 ^ v27) & 0x7F); v31 = v26 ^ v27 ^ v28 ^ v29; if ( (((unsigned __int8)v26 ^ v27) & 0x80) != 0 ) v30 ^= v23; *v25 = v30 ^ v26 ^ v31; v32 = 2 * ((v27 ^ v28) & 0x7F); if ( ((v27 ^ v28) & 0x80) != 0 ) v32 ^= v23; v25[1] = v32 ^ v27 ^ v31; v33 = 2 * ((v28 ^ v29) & 0x7F); if ( ((v28 ^ (unsigned __int8)v29) & 0x80) != 0 ) v33 ^= v23; v34 = v26 ^ v29; v25[2] = v33 ^ v28 ^ v31; v35 = 2 * (v34 & 0x7F); if ( (v34 & 0x80) != 0 ) v35 ^= v23; ++v24; v25[3] = v35 ^ v29 ^ v31; v25 += 4; } while ( v24 != 4 ); v18 = sub_4000F8(v20, v21 + v22, v25, v34); } while ( v36 != 144 ); v37 = (_BYTE *)sub_40011C(v18); v38 = sub_400144(v37); sub_4000F8(v38, &v140, v39, v40); byte_410FE8 ^= v133[10] ^ v133[15] ^ v133[0] ^ v133[5];
预处理代码:
// 0x400334: 将用户输入循环填充到 16 字节 for ( i = 0LL; i != 16; ++i ) { if ( v3 ) // 输入有内容 v8 = v132[i % v3]; // 循环取输入字符 else v8 = 17 * i; // 无输入时用 17*i 填充 v133[i] = v8 ^ byte_400B04[i]; // XOR 掩码 "migration-probe!" }
在 AES 加密完成后,代码只做了一行操作(0x40053C):
byte_410FE8 ^= v133[10] ^ v133[15] ^ v133[0] ^ v133[5];
byte_410FE8 在 .bss 段(0x410FE8),是个全局变量。用x快捷键在ida看看交叉引用(或者通过ctrl + F检索全部事件都可以看出:
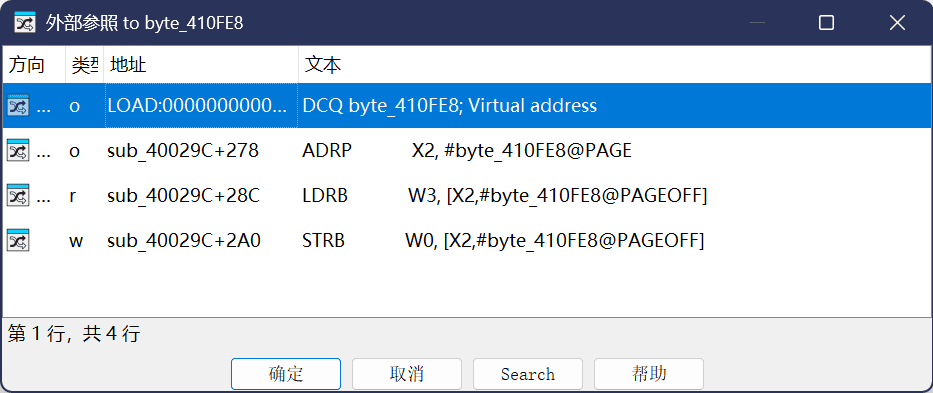
AES 的输出只被提取了 4 个字节异或成 1 个 checksum 字节,存到 BSS,后面再也没有使用过。AES 的输出完全不参与最终的 byte_400C70 比较。
链路:input → RC4 → XTEA → ChaCha20 XOR → compare
分析 RC4 ,RC4 密钥不是明文存储的,所以需要先分析解出,在0x40058C ~ 0x4005BC
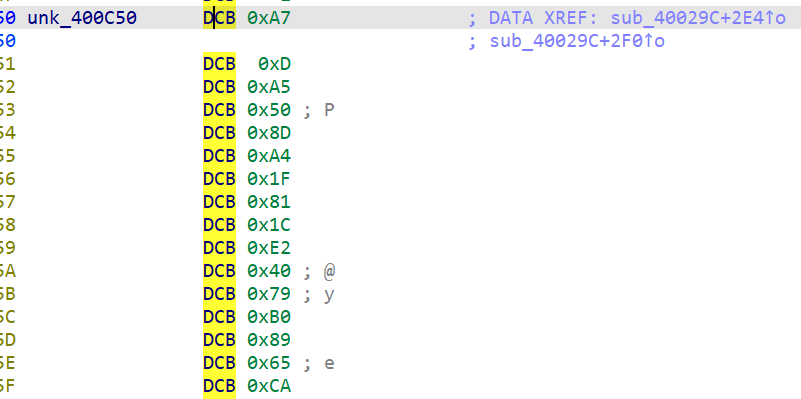
v44 = &unk_400C50;
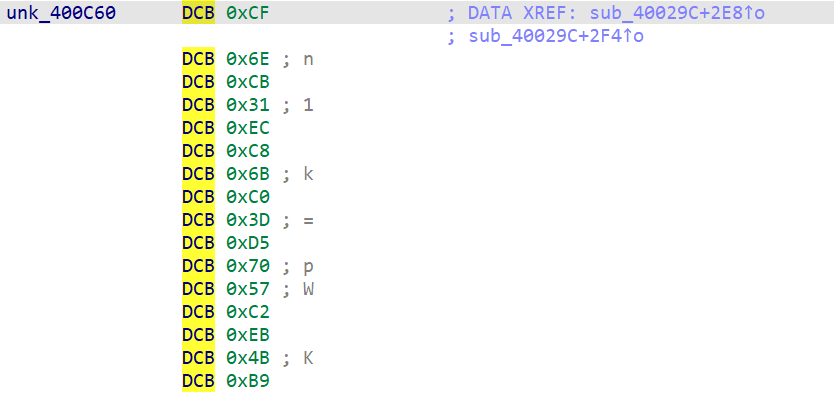
v45 = &unk_400C60;
v46 = &v124;
v47 = (unsigned __int8 *)&unk_400C4C;
for ( ii = 0LL; ii != 4; sub_4000F0(&v46[4 * v47[ii]], bswap32(v44[ii] ^ v45[ii]), ii + 1) )
;
程序在运行时从两组常量数组(0x400C50 和 0x400C60)做 XOR,所以:
查看数据区域,unk_400C50:
unk_400C60:
再经过 REV(字节反转)和索引置换表重排,得到 16 字节密钥:
RC4 Key = Atlas.branch.07!
脚本计算过程:

#!/usr/bin/env python3 # -*- coding: utf-8 -*- def bswap32(x: int) -> int: return ( ((x & 0x000000FF) << 24) | ((x & 0x0000FF00) << 8) | ((x & 0x00FF0000) >> 8) | ((x & 0xFF000000) >> 24) ) def main(): c50 = [0x50A50DA7, 0x811FA48D, 0x7940E21C, 0xCA6589B0] # 小端读取 c60 = [0x31CB6ECF, 0xC06BC8EC, 0x5770D53D, 0xB94BEBC2] perm = [2, 0, 3, 1] key_dwords = [0] * 4 for i in range(4): xored = c50[i] ^ c60[i] # XOR swapped = bswap32(xored) # 字节翻转 key_dwords[perm[i]] = swapped # 按排列表放置 # 按小端把4个DWORD拼成字节串,再转成ASCII字符串 key_bytes = b"".join(x.to_bytes(4, "little") for x in key_dwords) result = key_bytes.decode("ascii") print("key_dwords =", [hex(x) for x in key_dwords]) print("result =", result) if __name__ == "__main__": main()
然后继续往下看,分析具体的RC4 加密:
从0x400688开始,大概到0x4006F0:
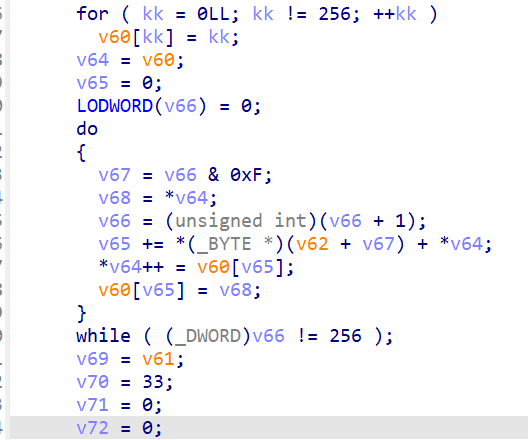
// 0x400688: KSA — 初始化 S-box for ( kk = 0; kk != 256; ++kk ) v60[kk] = kk; // S[i] = i // 0x4006A0: KSA — 密钥混洗 v65 = 0; // j = 0 v66 = 0; // i = 0 do { v67 = v66 & 0xF; // key_index = i & 0xF (密钥长 16) v68 = *v64; // S[i] v65 += key[v67] + *v64; // j += key[i%16] + S[i] *v64++ = v60[v65]; // swap S[i], S[j] v60[v65] = v68; } while ( v66++ != 256 ); // 0x4006F0: PRGA — 对 32 字节流加密 v70 = 33; // 循环次数(32+1,用 --v70 前置判断) v71 = 0; // i v72 = 0; // j while ( --v70 ) { v120 = S[++v72]; // i++; tmp = S[i] v71 += v120; // j += S[i] S[v72] = S[v71]; // swap S[i], S[j] S[v71] = v120; *v69++ ^= S[(S[v72] + v120) & 0xFF]; // output ^= S[S[i]+S[j]] }
识别特征:256 元素数组初始化 → j 累加 → swap → 输出异或,这是标准 RC4。
定位到 0x400704 处的嵌套循环,大概范围是0x400704 ~ 0x4007A4:

do { v74 = sub_4000E8(...); // 读取 v0 (uint32) v78 = sub_4000E8(...); // 读取 v1 (uint32) v83 = 0; // sum = 0 do { // 内层: 32 轮 v84 = v83 + *(v80 + 4 * (v83 & 3)); // sum + key[sum & 3] v83 += v81; // sum += delta (0x9E3779B9) v77 += v84 ^ (((v78 >> 5) ^ (16 * v78)) + v78); // v0 更新 // sum += delta 在 v0 和 v1 之间 v78 += (v83 + key[(v83 >> 11) & 3]) ^ (((v77 >> 5) ^ (16 * v77)) + v77); // v1 更新 } while ( v83 != v82 ); // sum == delta * 32 时结束 sub_4000F0(..., v77, v78); // 写回 v0, v1 v73 += 8; // 下一个块 } while ( v88 != 32 ); // 处理完 32 字节
识别特征:(v >> 5) ^ (v << 4) + sum & 3 / (sum >> 11) & 3 = XTEA 经典结构
32 轮,delta=0x9e3779b9,4 个 8 字节块。密钥由 MOV+MOVK 立即数指令直接构造:
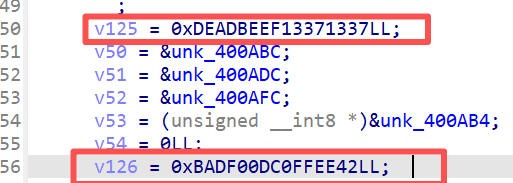
v125 = 0xDEADBEEF13371337LL; // key[0]=0x13371337, key[1]=0xDEADBEEF v126 = 0xBADF00DC0FFEE42LL; // key[2]=0xC0FFEE42, key[3]=0x0BADF00D
这个实现里 sum += delta 的位置和标准 TEA 不同,是在 v0 和 v1 的更新之间,而不是在两个更新之前。所以用标准的 TEA 解密函数会算出错误结果,必须按照反编译出来的精确顺序来。
定位到大约0x4007AC ~ 0x400944:
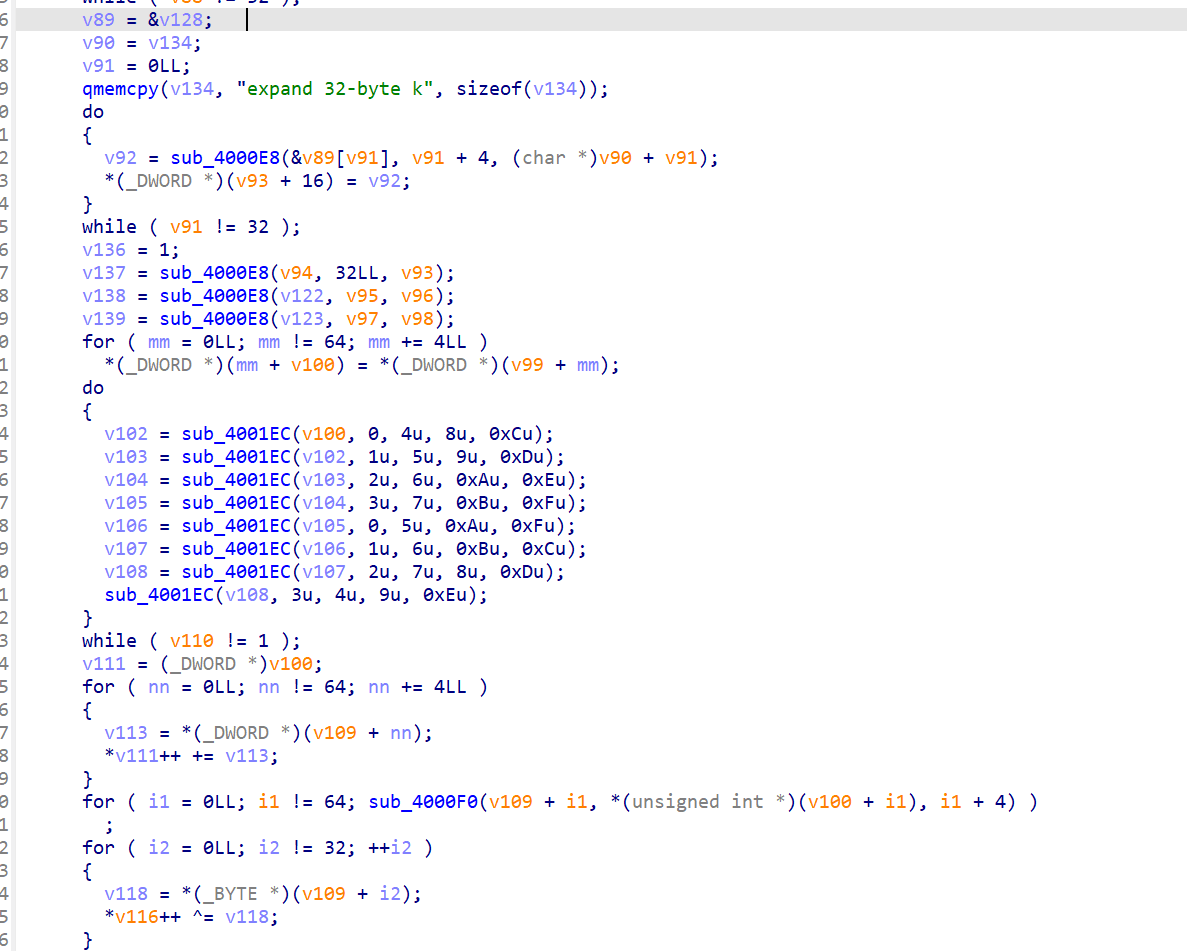
// 0x4007C4: 加载 ChaCha20 常量 qmemcpy(v134, "expand 32-byte k", sizeof(v134)); // state[0..3]
ChaCha20 state 布局(16 个 uint32):
state[0..3] = "expand 32-byte k" (0x61707865, 0x3320646E, 0x79622D32, 0x6B206574)
state[4..11] = 32 字节密钥
state[12] = counter (= 1, 在 0x4007FC 处设置: v136 = 1)
state[13..15]= 12 字节 nonce
QuarterRound 调用(0x400858 ~ 0x4008EC):
// 每次双轮 = 4 列轮 + 4 对角轮 do { sub_4001EC(v100, 0, 4, 8, 0xC); // 列轮 0 sub_4001EC(..., 1, 5, 9, 0xD); // 列轮 1 sub_4001EC(..., 2, 6, 0xA, 0xE); // 列轮 2 sub_4001EC(..., 3, 7, 0xB, 0xF); // 列轮 3 sub_4001EC(..., 0, 5, 0xA, 0xF); // 对角轮 0 sub_4001EC(..., 1, 6, 0xB, 0xC); // 对角轮 1 sub_4001EC(..., 2, 7, 8, 0xD); // 对角轮 2 sub_4001EC(..., 3, 4, 9, 0xE); // 对角轮 3 } while ( v110 != 1 ); // 10 次双轮 = 20 轮
查看 sub_4001EC(QuarterRound)的反编译
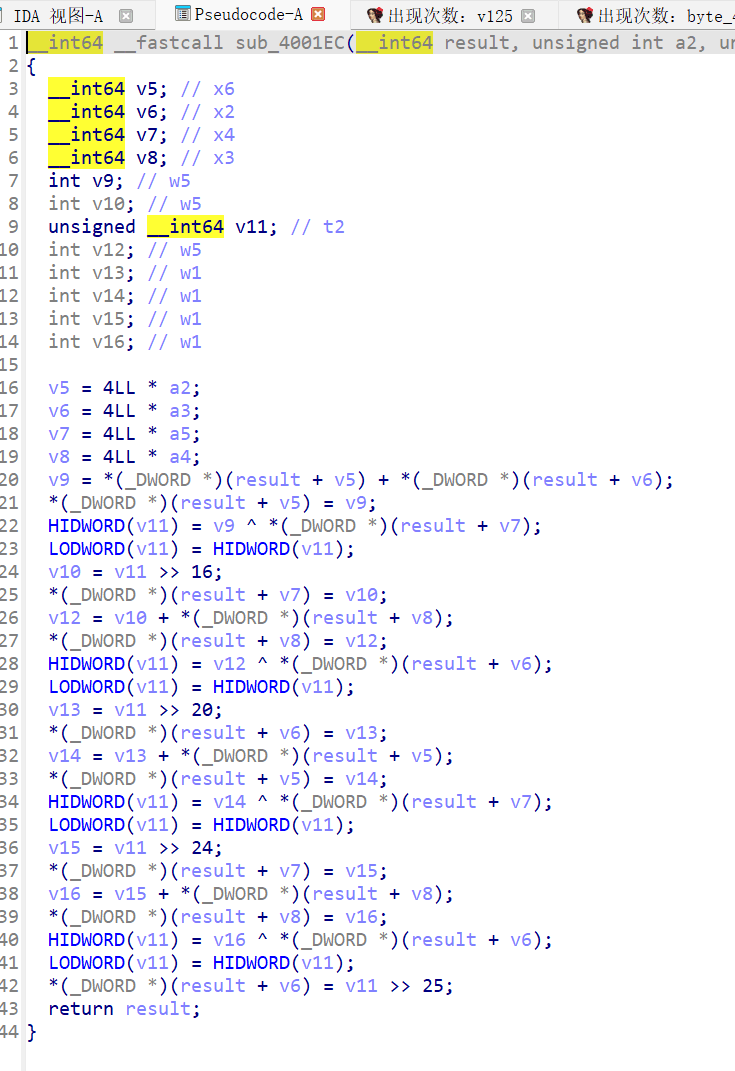
a += b; d ^= a; d = ROL(d, 16); // v11 >> 16 c += d; b ^= c; b = ROL(b, 12); // v11 >> 20 a += b; d ^= a; d = ROL(d, 8); // v11 >> 24 c += d; b ^= c; b = ROL(b, 7); // v11 >> 25
这里学到了识别特征:旋转量 16/12/8/7 是 ChaCha20 的标志性常量。
标准的 20 轮 ChaCha20 分组函数。ChaCha20 密钥(32 字节)由 ADD + ROR + permute 生成:

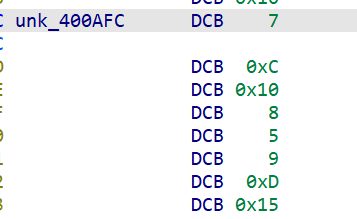
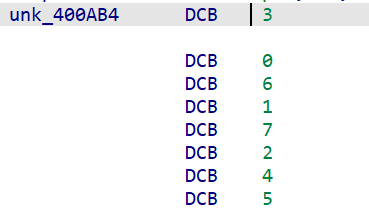
| 地址 | 数据 | 含义 |
|---|---|---|
| 0x400ABC | 8 个 dwords | 常量组 1 |
| 0x400ADC | 8 个 dwords | 常量组 2 |
| 0x400AFC | 8 bytes | ROR 旋转量 |
| 0x400AB4 | 8 bytes | 排列表 |
for i in range(8): s = (abc[i] + adc[i]) & 0xFFFFFFFF chacha_key[perm[i]] = ROR32(s, rot[i]) # 结果: "mobile-vault-transition-key!2026"
ChaCha20 Key = mobile-vault-transition-key!2026
ChaCha20 Nonce(12 字节)由 XOR + bswap + permute 生成:

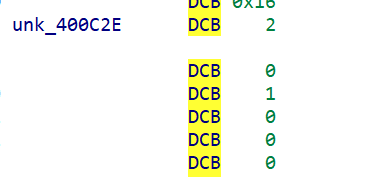
| 地址 | 数据 | 含义 |
|---|---|---|
| 0x400C34 | 3 个 dwords | 常量组 1 |
| 0x400C40 | 3 个 dwords | 常量组 2 |
| 0x400C2E | 3 bytes 02 00 01 | 排列表 |
for i in range(3): nonce[perm[i]] = bswap32(c34[i] ^ c40[i]) # 结果: "arm64-nonce!"
Nonce = arm64-nonce!
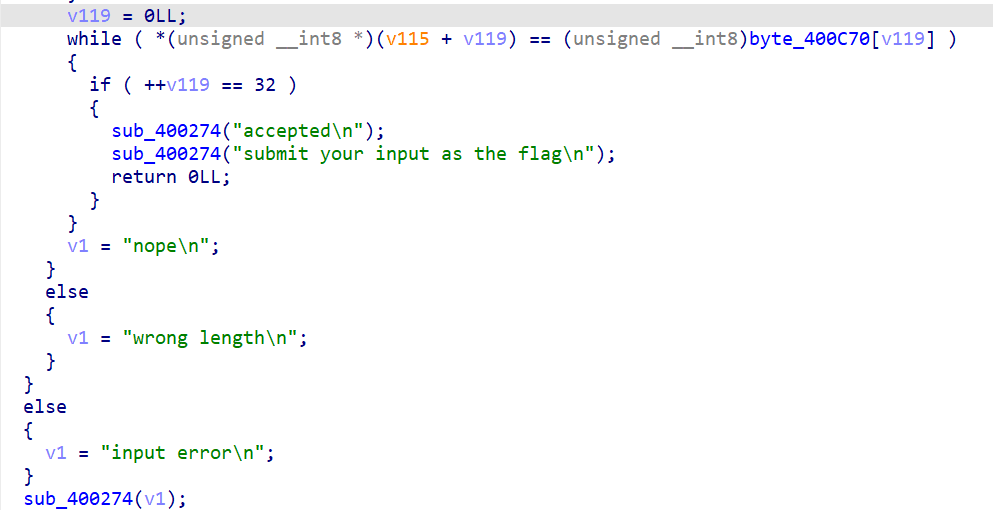
// 0x400958: 逐字节比较 v119 = 0; while ( input[v119] == byte_400C70[v119] ) { if ( ++v119 == 32 ) { sub_400274("accepted\n"); sub_400274("submit your input as the flag\n"); return 0; } } sub_400274("nope\n");
期望密文 byte_400C70(32 字节):
DE 21 9A 75 C1 83 7A 5A D3 B0 51 40 C3 B4 F1 A8
0A 1F 79 7F CD 0A 23 55 5C AC 7A 30 C7 48 E0 FB

既然正向链路是 RC4 → XTEA → ChaCha20,那解密就反过来:
- 生成 ChaCha20 密钥流,XOR 解密密文
- XTEA 解密(4 个块)
- RC4 解密(流密码直接再跑一次即可)
#!/usr/bin/env python3 """ legacy_vault solver Flag: flag{arm64_rc4_xtea_chacha_2026} Algorithm chain (forward): input (32 bytes) -> RC4 -> XTEA -> ChaCha20 XOR -> compare with expected Decoy: AES-128 (SubBytes/ShiftRows/MixColumns with "Vault-AES-stub-1" key) Only computes a checksum byte, not part of the comparison. Key material is derived at runtime via XOR/ADD/ROR/REV of embedded constant pairs. """ import struct # ---- Read binary data ---- with open("/mnt/e/pore/pore_24300240030/pj1/PJ1-Handout/07-easyre/legacy_vault", "rb") as f: binary = f.read() def read_bytes(vaddr, length): return bytearray(binary[vaddr - 0x400000 : vaddr - 0x400000 + length]) def read_dwords(vaddr, count): raw = read_bytes(vaddr, count * 4) return [struct.unpack("<I", raw[i*4:(i+1)*4])[0] for i in range(count)] # ---- Derive RC4 key (16 bytes) from two constant arrays + XOR + REV + permutation ---- dwords_c50 = read_dwords(0x400C50, 4) dwords_c60 = read_dwords(0x400C60, 4) perm_c4c = read_bytes(0x400C4C, 4) rc4_key_dwords = [0] * 4 for i in range(4): v = dwords_c50[i] ^ dwords_c60[i] v_rev = struct.unpack(">I", struct.pack("<I", v))[0] # byte-swap rc4_key_dwords[perm_c4c[i]] = v_rev rc4_key = b"".join(struct.pack("<I", w) for w in rc4_key_dwords) assert rc4_key == b"Atlas.branch.07!", f"RC4 key mismatch: {rc4_key}" # ---- Derive ChaCha20 key (32 bytes) from ADD + ROR + permutation ---- dwords_abc = read_dwords(0x400ABC, 8) dwords_adc = read_dwords(0x400ADC, 8) rot_afc = read_bytes(0x400AFC, 8) perm_ab4 = read_bytes(0x400AB4, 8) chacha_key = [0] * 8 for i in range(8): s = (dwords_abc[i] + dwords_adc[i]) & 0xFFFFFFFF r = rot_afc[i] chacha_key[perm_ab4[i]] = ((s >> r) | (s << (32 - r))) & 0xFFFFFFFF chacha_key_bytes = b"".join(struct.pack("<I", w) for w in chacha_key) assert chacha_key_bytes == b"mobile-vault-transition-key!2026" # ---- Derive ChaCha20 nonce (12 bytes) from XOR + REV + permutation ---- dwords_c34 = read_dwords(0x400C34, 3) dwords_c40 = read_dwords(0x400C40, 3) perm_c2e = read_bytes(0x400C2E, 3) nonce = [0] * 3 for i in range(3): v = dwords_c34[i] ^ dwords_c40[i] nonce[perm_c2e[i]] = struct.unpack(">I", struct.pack("<I", v))[0] nonce_bytes = b"".join(struct.pack("<I", w) for w in nonce) assert nonce_bytes == b"arm64-nonce!" # ---- XTEA key (hardcoded immediates) ---- xtea_key = [0x13371337, 0xDEADBEEF, 0xC0FFEE42, 0x0BADF00D] # ---- Expected ciphertext ---- expected = read_bytes(0x400C70, 32) # ========== Crypto primitives ========== def rc4_crypt(key, data): S = list(range(256)) j = 0 for i in range(256): j = (j + S[i] + key[i % len(key)]) & 0xFF S[i], S[j] = S[j], S[i] i = j = 0 out = bytearray() for b in data: i = (i + 1) & 0xFF j = (j + S[i]) & 0xFF S[i], S[j] = S[j], S[i] out.append(b ^ S[(S[i] + S[j]) & 0xFF]) return out def xtea_decrypt_block(block, key): """Modified TEA (XTEA-like): sum updates between the two half-rounds.""" v0, v1 = struct.unpack("<II", block) delta = 0x9E3779B9 s = 0xC6EF3720 # delta * 32 for _ in range(32): v1 = (v1 - ((((v0 << 4) ^ (v0 >> 5)) + v0) ^ (s + key[(s >> 11) & 3]))) & 0xFFFFFFFF s = (s - delta) & 0xFFFFFFFF v0 = (v0 - ((((v1 << 4) ^ (v1 >> 5)) + v1) ^ (s + key[s & 3]))) & 0xFFFFFFFF return struct.pack("<II", v0, v1) def chacha20_block(key8, counter, nonce3): def qr(s, a, b, c, d): s[a]=(s[a]+s[b])&0xFFFFFFFF; s[d]^=s[a]; s[d]=((s[d]<<16)|(s[d]>>16))&0xFFFFFFFF s[c]=(s[c]+s[d])&0xFFFFFFFF; s[b]^=s[c]; s[b]=((s[b]<<12)|(s[b]>>20))&0xFFFFFFFF s[a]=(s[a]+s[b])&0xFFFFFFFF; s[d]^=s[a]; s[d]=((s[d]<<8)|(s[d]>>24))&0xFFFFFFFF s[c]=(s[c]+s[d])&0xFFFFFFFF; s[b]^=s[c]; s[b]=((s[b]<<7)|(s[b]>>25))&0xFFFFFFFF state = [0x61707865, 0x3320646E, 0x79622D32, 0x6B206574] + list(key8) + [counter] + list(nonce3) w = list(state) for _ in range(10): qr(w,0,4,8,12); qr(w,1,5,9,13); qr(w,2,6,10,14); qr(w,3,7,11,15) qr(w,0,5,10,15); qr(w,1,6,11,12); qr(w,2,7,8,13); qr(w,3,4,9,14) return b"".join(struct.pack("<I", (w[i]+state[i])&0xFFFFFFFF) for i in range(16)) # ========== Reverse the chain ========== # 1) Generate ChaCha20 keystream and XOR chacha_ks = chacha20_block(chacha_key, 1, nonce) step1 = bytearray(expected[i] ^ chacha_ks[i] for i in range(32)) # 2) XTEA decrypt (4 blocks of 8 bytes) step2 = bytearray() for i in range(4): step2.extend(xtea_decrypt_block(step1[i*8:(i+1)*8], xtea_key)) # 3) RC4 decrypt password = rc4_crypt(rc4_key, step2) print("Password:", password.decode("ascii")) # flag{arm64_rc4_xtea_chacha_2026}

$ echo 'flag{arm64_rc4_xtea_chacha_2026}' | qemu-aarch64 -L /usr/aarch64-linux-gnu ./legacy_vault
== Legacy Vault ==
Three migrations later, only the master password still works.
Password: accepted
submit your input as the flag
- flag:
flag{arm64_rc4_xtea_chacha_2026}