
![[FDUCTF 2026冬令营] Web安全入门指北](https://lunaticquasimodo.top/uploads/Weixin_Image_20251127215810_517_1118_e0cc183e0d.png)
By LunaticQuasimodo
观前提示:
内容可能比较详细,对于零基础的同学而言,关注划的重点、脑子里有个基础印象即可,具体内容还是需要讲师讲解来辅助理解。优先有个知识印象,只是为了让大家在听课时不至于一头雾水;工具的下载一定要提前配好,我们授课时会直接使用,不会教太多安装使用。
不会的问AI!!!不会的问AI!!!不会的问AI!!!
然后再在群里问!
划重点:HTTP协议、web服务搭建、常见web漏洞、web工具下载与使用、代码学习
既然是web方向的入门指南,首先需要先弄清楚web指的是什么。广义来讲,CTF里的Web是指:把“计算机网络里学到的 Web 通信机制(HTTP/HTTPS、Cookie、会话、缓存、代理、DNS…)”搬到一个“有意设计缺陷/边界情况”的网站里,让你通过分析网络交互、构造请求,最终拿到 flag。
而对于计算机网络中的web,其实就是针对于应用层的一种网络框架,狭义理解、也是我们ctf中基本上只会遇到的web类型——就是我们随处可见的各种网站。
因此,要入门web方向的ctf学习,首先可能需要学习和理解一些有关计算机网络的相关知识:
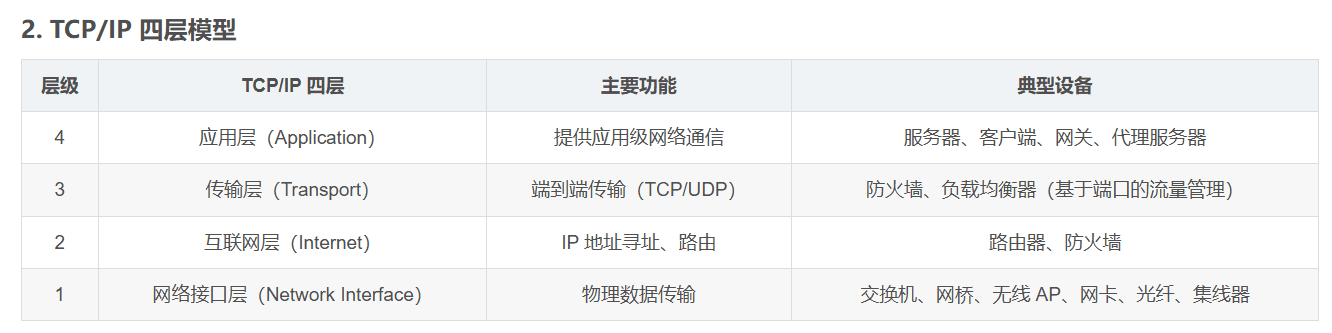
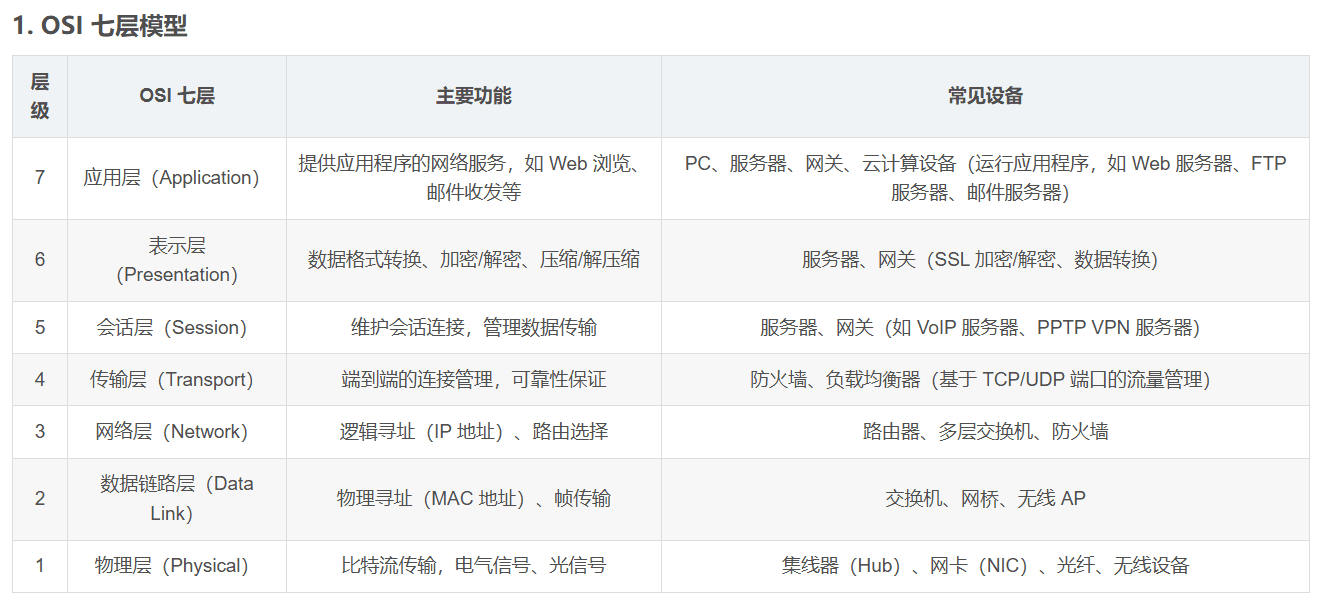
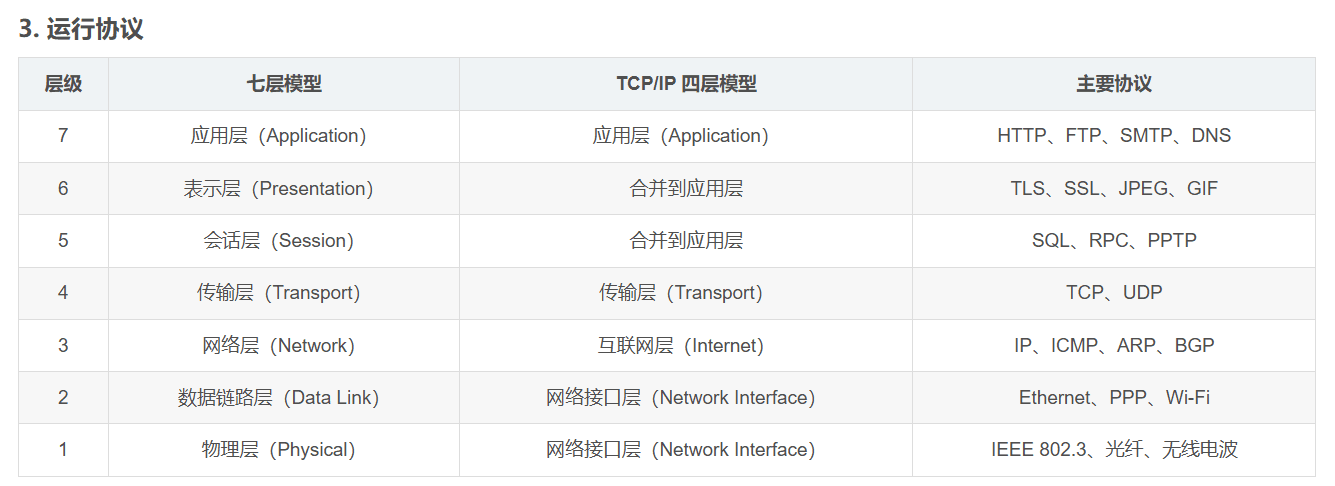
这是学界公认的两种描述计算机网络的主要模型,我们的web,就主要集中于模型最顶层的应用层模块(OSI中的应用、表示、会话层,对应IP模型中的应用层),基本上不需要考虑其他层级的作用。可以简单理解为,web只需要考虑如何运用现有条件功能来构建一个网站应用,而不需要考虑底层提供的细节。
而对于web而言,客户端和服务端的通信,基本上都是通过应用层的HTTP协议进行,通过HTTP报文进行交互,所以我们还需要学习HTTP协议和报文,这部分是重中之重。
画外音:由于FDU把计算机网络放在培养方案比较靠后的位置,这儿的内容对于低年级的同学可能不太熟悉,感兴趣的可以多去了解了解,但不是我们的重点
HTTP(HyperText Transfer Protocol) 是浏览器和服务器之间“说话”的规则。
- 客户端(Client):浏览器、curl、脚本、Burp Repeater
- 服务端(Server):网站后端(Nginx/Apache + 应用代码)
- 交互方式:客户端发一个 请求(Request),服务器回一个 响应(Response)
- 特点
- 基于 TCP(HTTPS 则是 TCP + TLS)
- 无状态:服务器默认不“记住你”,所以要用 Cookie / Session / Token 来维持登录状态
- 常用端口:HTTP 80,HTTPS 443
Web 题的本质就是:控制和理解请求/响应,从而触发漏洞或绕过限制,例如:
- 改参数(GET/POST、JSON、表单、数组参数)
- 改请求头(User-Agent、Referer、X-Forwarded-For)
- 改 Cookie / Token(会话伪造、越权)
- 观察响应(状态码、跳转、Set-Cookie、报错栈)
HTTP 报文分两大类:请求 和 响应。它们都遵循“起始行 + 头部 + 空行 + 正文”结构。
A. 请求报文(Request)
请求行:
METHOD PATH HTTP/VERSION
例子:
GET /index.php?id=1 HTTP/1.1
请求头(Headers):一行一个 Key: Value
空行:表示头结束
请求体(Body,可选):POST/PUT 常有
完整例子:
POST /login HTTP/1.1 Host: example.com User-Agent: Mozilla/5.0 Content-Type: application/x-www-form-urlencoded Cookie: session=abc123 Content-Length: 27 username=admin&pwd=123
B. 响应报文(Response)
状态行:
HTTP/VERSION STATUS_CODE STATUS_TEXT
例子:
HTTP/1.1 200 OK
响应头:同样是 Key: Value
空行
响应体:HTML/JSON/图片/下载文件等
例子:
HTTP/1.1 302 Found Location: /home Set-Cookie: session=def456; HttpOnly <html>...</html>
请求常见字段
Host:你要访问的域名(HTTP/1.1 必须有)Cookie:浏览器带给服务器的“身份信息”Content-Type:请求体格式application/x-www-form-urlencoded(表单)application/json(JSON)multipart/form-data(文件上传)
Authorization:Bearer Token / Basic 等Referer/Origin:常用于 CSRF 判断User-Agent:题目可能用它做简单过滤X-Forwarded-For:伪造来源 IP(有些题会信这个)
响应常见字段
Set-Cookie:服务器让浏览器存 Cookie(维持登录)Location:配合302/301跳转Content-Type:返回内容类型(HTML/JSON等)Content-Length:正文长度Server:可能泄露服务器信息(CTF 里有时有用)
- GET:取资源(参数通常在 URL 上)
GET /search?q=ctf - POST:提交数据(参数通常在 Body)
POST /login - PUT/DELETE:REST 风格 API 会出现(偶尔遇到)
- HEAD:只要响应头,不要正文(调试用)
- 2xx 成功
200 OK:正常返回
- 3xx 跳转
301/302:看Location,常见“登录后跳转”
- 4xx 客户端问题
401 Unauthorized:没认证(缺 token/cookie)403 Forbidden:被禁止(权限/黑名单/拦截)404 Not Found:资源不存在(或被隐藏)
- 5xx 服务端问题
500 Internal Server Error:后端异常(CTF 中常能爆栈/SQL报错/路径泄露)
拿到一个站点进行分析的流程
- 先抓包(浏览器开发者工具 Network / Burp)
- 看请求:
- URL 路径、参数(GET query / POST body)
- Cookie / Token 是否变化
- Content-Type 是表单还是 JSON
- 看响应:
- 状态码(200/302/403/500)
- Set-Cookie 有没有发新会话
- 返回体是 HTML 还是 JSON,是否含报错
- 改包测试(Repeater):
- 改参数值、增删参数、改请求方法(GET↔POST)
- 改请求头(Referer/Origin/User-Agent)
- 改 Cookie / 伪造身份字段(越权)
- 关注“差异”:
- 同一个接口,不同输入导致响应长度/状态码/内容差异 → 往往就是突破口
- HTTP:明文传输,抓包能直接看到账号密码/参数
- HTTPS:HTTP 外面加了 TLS 加密,内容默认看不到(能用浏览器 DevTools 或 Burp 配证书进行调试)
WEB的组成框架模型:网站源码、操作系统、中间件(搭建平台,提供服务的)、数据库。
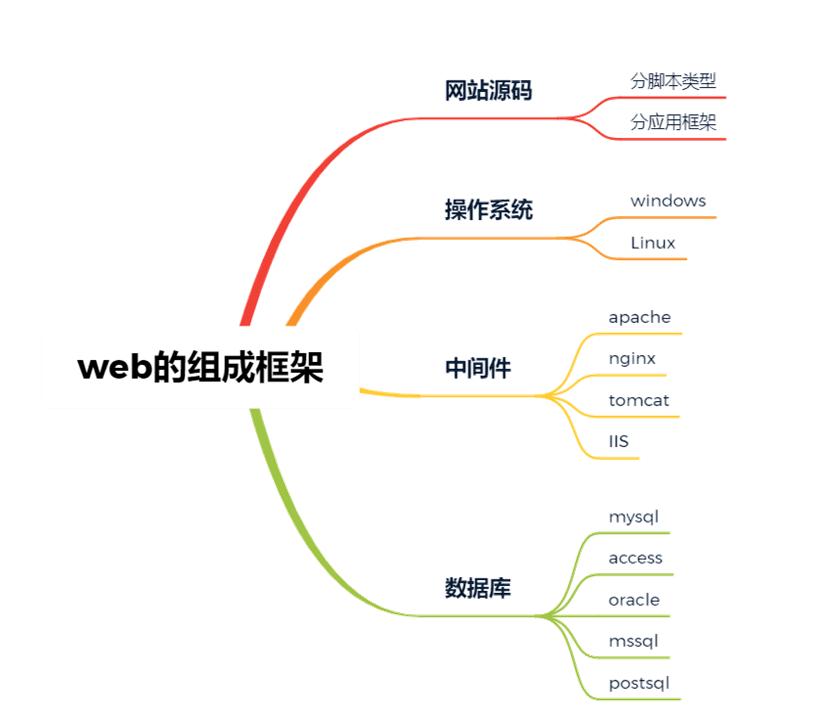
这张图应该给的很清晰了,每个部分的详细讲解如下:
下面这些有的其实是AI生成的内容讲解,绝对正确但是对于新手而言,你可能不需要了解这么多。
目的是你只需要知道每个部分的作用是干嘛,脑子里有个印象就行了,具体情况还是要具体分析,上课的时候听我讲就行啦 ~
作用:
- 真正“决定网站做什么”的地方:登录、注册、查询、上传、权限判断、生成页面、返回 JSON 等。
- 把用户输入(URL 参数、表单、JSON、Cookie…)变成业务逻辑处理结果。
内容(图里分两类):
① 分脚本类型(后端语言/运行时)
常见:PHP、Python(Flask/Django)、Java(Spring)、JavaScript(Node/Express)、C#(ASP.NET)、Go…
它决定:
- 代码如何运行(解释/编译、运行环境)
- 常见库与生态
- 输入处理习惯(比如模板渲染、反序列化方式等)
② 分应用框架(框架/项目结构)
常见:Django/Flask、Spring MVC、Laravel、ThinkPHP、Express、ASP.NET MVC…
框架通常提供:
- 路由(URL → 哪个函数处理)
- 模板渲染(生成 HTML)
- 会话/认证(session、token)
- 数据库访问(ORM)
- 安全/中间件机制(CSRF、过滤器等)
作用
- 给所有服务提供运行环境:进程、文件系统、网络栈、权限模型、环境变量。
- 你看到的 Web 服务(Nginx、Tomcat、MySQL)都只是 OS 上跑的进程。
内容
- 文件系统与路径规则:Linux
/var/www/...,WindowsC:\inetpub\... - 权限与用户:哪些进程能读写哪些文件(最关键)
- 网络与端口:80/443/3306 等端口监听、iptables/防火墙
- 日志与计划任务:logrotate、cron、Windows 计划任务
可以把中间件理解为“Web 请求的接待员 + 分发员”。
作用:
- 接收 HTTP/HTTPS:监听端口、TLS 终止(HTTPS 解密)
- 处理通用功能:
- 静态资源(css/js/img)直接返回
- 反向代理/转发请求给后端应用
- 压缩、缓存、限流、日志记录、重写规则(rewrite)
- 把请求交给“网站源码”运行环境
- Nginx/Apache → PHP-FPM(FastCGI)/uwsgi/gunicorn
- Nginx → Node/Spring 等(proxy_pass)
- Tomcat 直接跑 JSP/Servlet(Java Web 容器)
- IIS 常配 ASP.NET
例子:
- Nginx:高性能反向代理/静态资源强,常做“前门”
- Apache:模块多,传统 Web 服务器
- Tomcat:Java Web 应用服务器/容器(跑 JSP/Servlet/Spring)
- IIS:Windows 下的 Web 服务器,常配 ASP.NET
作用:
- 持久化存储数据:用户表、权限、题目、订单、日志等。
- 提供查询语言(SQL)让应用按条件取数据、更新数据。
内容:
- 数据库实例/账号权限
- 表结构、索引、事务
- 备份文件、日志、存储过程(不同数据库能力不同)
不同数据库的区别
- MySQL:最常见,Web 题生态最多,也是国内数据库生态的绝对龙头
- PostgreSQL:语法/函数和 MySQL 有差异,但是性能更好
- MSSQL:Windows 环境常见,特性不同 (不用管)
- Oracle:企业常见,语法体系又不同 (不用管)
- Access:一些老系统/练习题会出现 (不用管)
请看下图:
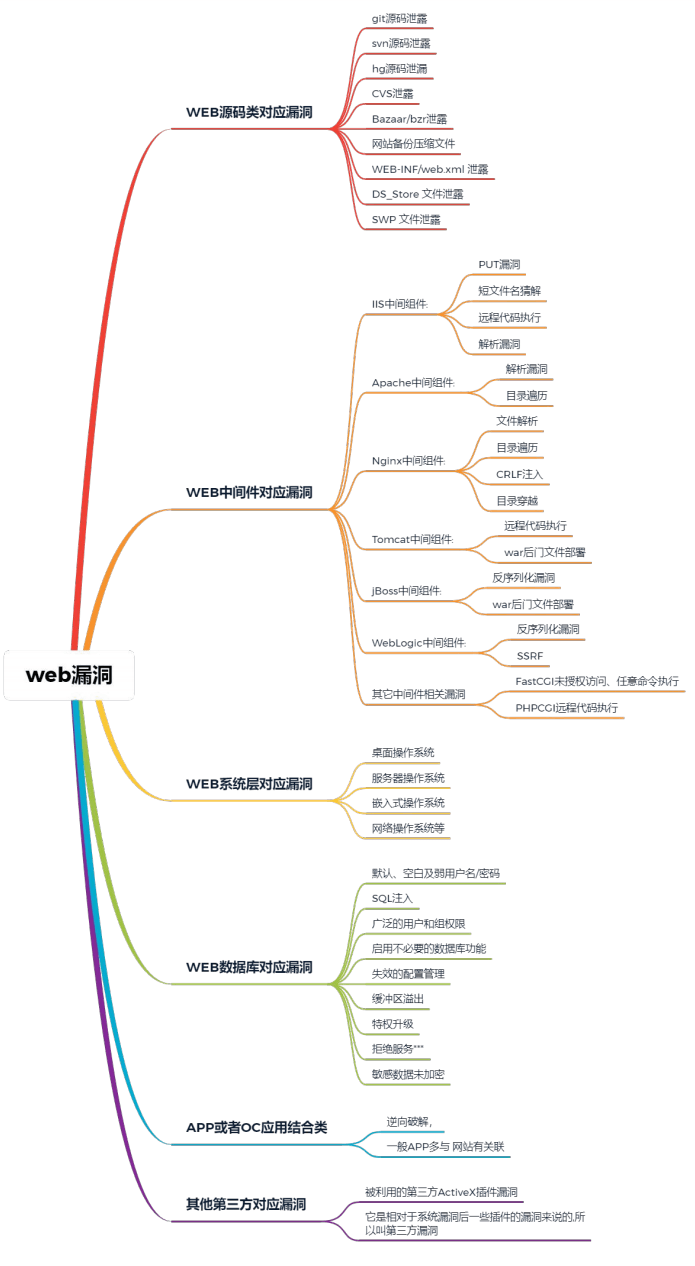
有没有被吓到hhhh
但其实,我们只需要关注最常见的几大最主流、传统web安全漏洞即可,下面作为一些简要了解概述;
让你注入的内容在别人浏览器里当作脚本执行。
本质:数据被当成代码(浏览器端执行)。
常见入口:评论/昵称/搜索框/富文本、URL 参数反射到页面、前端模板渲染、DOM 拼接(innerHTML)。
危害:窃取 Cookie/Token、冒充用户操作、钓鱼页面、读页面敏感信息。
把你的输入拼进 SQL查询语句,导致你能改查询逻辑甚至读/改数据库中的数据。
本质:数据进入查询语句结构(没有参数化)。
常见入口:登录、搜索、id=... 详情页、排序字段、过滤条件;以及“只对前端校验”的接口。
危害:绕过登录、读取敏感数据、写入数据、在某些配置下进一步拿到服务器权限。
钓鱼网站/链接工作原理,也就是窃取用户状态信息(比如Cookie、token)进行身份请求伪造
本质:浏览器会自动携带 Cookie,网站又只用 Cookie 认人、不验证“请求是否来自本站”。
常见入口:改密码、转账、绑定邮箱、发帖、改资料等“有副作用”的接口。
危害:在用户不知情下完成敏感操作(前提:用户已登录)。
让服务器替你去访问一个 URL(包括内网/云元数据)。
本质:服务器端“帮你请求”,且你能控制目标地址。
常见入口:图片/URL 预览、Webhook、导入远程资源、在线解析。
危害:探测内网、打到内网服务、读云环境元数据。
木马的原理,上传一个看起来无害的文件,结果被当成脚本/可执行内容处理。
本质:文件类型校验不严 + 服务器解析/访问策略有问题。
常见入口:头像上传、附件上传、富文本图片上传。
危害:从信息泄露到远程代码执行(取决于是否能被执行/包含/解析)。
控制文件路径,让服务器读/写到不该碰的敏感文件。
本质:把用户输入当成文件路径的一部分,且未做规范化与边界检查。
常见入口:?file=xxx 下载/预览接口、读取模板/语言包、图片/附件访问、日志查看。
危害:读敏感文件(配置、源码、密钥)、有时还能覆盖写文件(更危险)。
应用把“文件路径”交给解释器去 include/require/render,导致你能让它加载不该加载的文件。
- LFI:包含本地文件(Local File Inclusion)
- RFI:包含远程文件(Remote File Inclusion,现代默认多被禁用/难度更高)
针对?page=home、?template=...、?lang=...、?view=... 这种“选择页面/模板/语言包”的参数进行注入
常和文件上传漏洞进行搭配,作为木马文件的读取方式
本该只在服务器执行/保密的源代码,被当作静态文件下载或被错误暴露。
常见原因:
- 备份文件暴露:
*.bak、*.swp、*.old、*~、backup.zip .git泄露- Web 服务器/解析配置错误(把动态当静态吐出来)
- LFI/路径遍历导致读到源码
危害:
- 直接拿到:数据库账号、密钥、第三方 token、隐藏接口、反序列化点、调试路由
- 确定网站搭建源码和逻辑,可以直接在本地分析
服务端用模板引擎渲染页面时,把用户输入当成“模板表达式”执行了。
应用把用户可控的序列化数据(对象)还原成对象时,触发危险魔术方法/链,导致执行意外逻辑甚至代码执行。
这个需要结合具体的语言学习,常见的反序列化漏洞语言:php、java等。
对于这一部分,其实我没什么资格教别人,本人的代码能力也堪忧,也是从大学开始才接触编程,所以我很理解新手的困境和瓶颈。
不过不用慌,其实在web方向CTF里面需要用到的代码能力不是很深入,不需要像打算法竞赛一样,只需要多了解各种语言的语法和逻辑就可以了,更何况在AI时代,我们还能问GPT老师来辅助我们进行代码学习和审计。
想要深入和系统性学习各种语言代码的,推荐去菜鸟教程进行学习,网站如下:
对于本次冬令营授课,我们
- 核心语言:HTML(结构)、CSS(样式)、JavaScript(交互/逻辑)
- 需要会的:DOM、事件、表单提交、Fetch/AJAX、Cookie/LocalStorage、同源策略/CORS
- 常见框架:Vue / React(了解即可,CTF 更偏看懂代码、改请求)
- 核心概念:路由(URL→函数)、请求/响应、鉴权与会话(Cookie/Session/JWT)、文件上传、模板渲染、API(JSON)
- 常见语言/框架栈:
- PHP(最常见的语言之一,上世纪的老古董但是很重要,大部分题还在用)
- Python(Flask/Django)
- Java(Spring)
- JavaScript(Node/Express)
- C#(ASP.NET)
- 需要会的:如何取参数、如何拼 SQL/调用系统、如何做权限校验
- 主流:MySQL / PostgreSQL / SQLite(入门优先 MySQL/SQLite)
- 需要会的 SQL:
SELECT / WHERE / ORDER BY / LIMIT / JOIN,以及常见函数/类型
Web的工具纷繁复杂,但是入门而言只需要安装主要用的少部分即可,请按照下面顺序作为优先级依次安装:
对于Linux系统,我们默认大家都按照wsl的安装教程已经安装好了wsl,配置好了linux发行版,没有弄好的,请参阅文档或者网络搜索、问AI解决。
这个工具学web是绕不开的,安装链接和一些基本使用,在该工具官方网站已经很详细了,请自行安装、简要学习:
注意:你可以选择在官网安装免费的社区版本,大概是够用的;你也可以选择去找一些专业版的破解资源,这个就八仙过海各显神通了,我不提供资源。
对于文件上传漏洞和webshell获取,这个软件也是绕不开的不二之选。
官方github链接:
https://github.com/AntSwordProject/antSword
请自行阅读安装,不会的问ai
专用于路径遍历扫描的工具
官方github链接:
https://github.com/maurosoria/dirsearch
请自行阅读安装,不会的问ai