

作者:陈诗宇 | 复旦大学"智能系统安全实践"课程总结与扩展
AI 系统的安全威胁覆盖其整个生命周期:数据收集、模型训练、模型部署、在线推理,每个阶段的攻击面不同,单点防御不可能奏效。


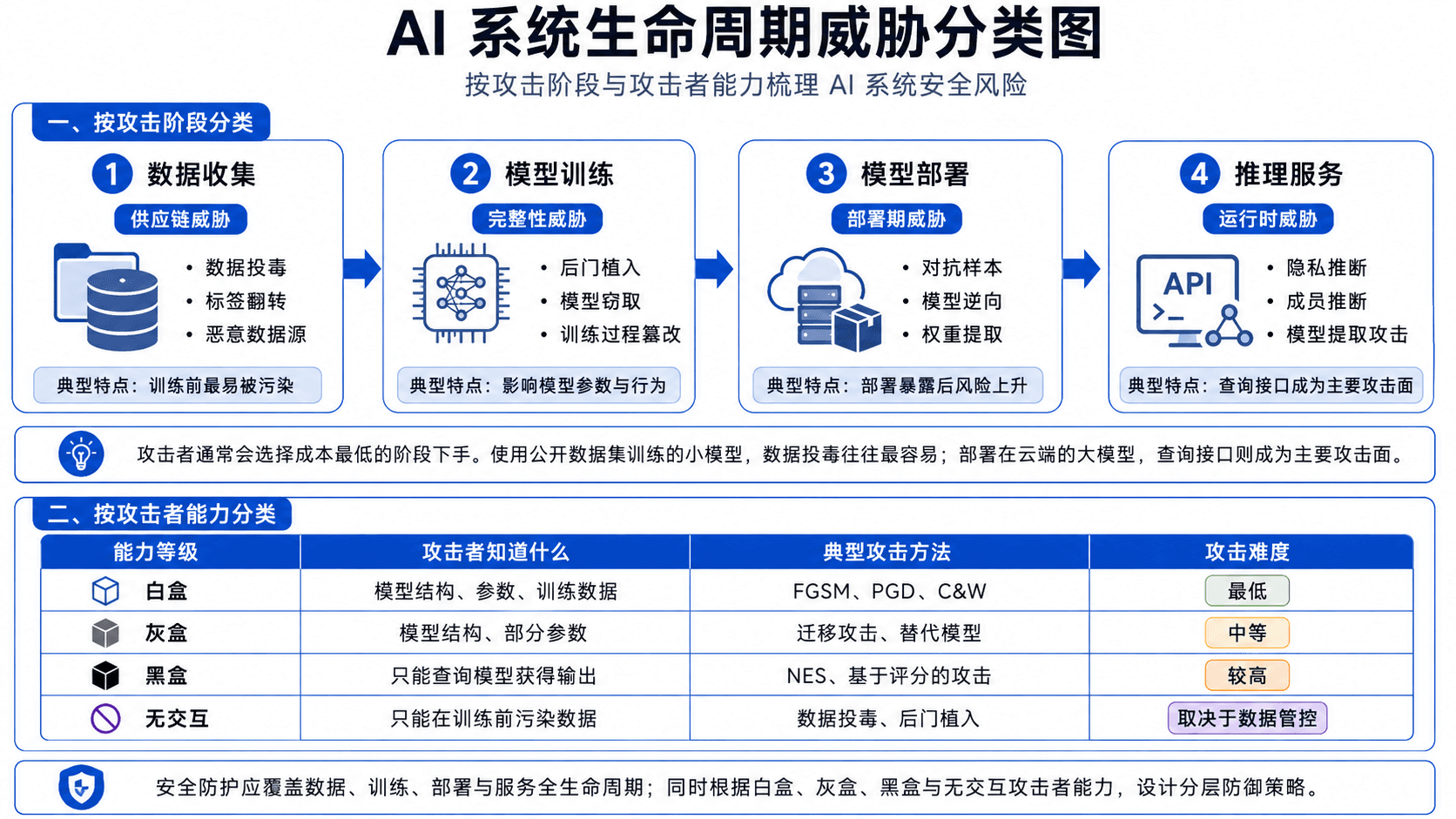
| 阶段 | 威胁类型 | 具体攻击 |
|---|---|---|
| 数据收集 | 供应链威胁 | 数据投毒、标签翻转、恶意数据源 |
| 模型训练 | 完整性威胁 | 后门植入、模型窃取、训练过程篡改 |
| 模型部署 | 部署期威胁 | 对抗样本、模型逆向、权重提取 |
| 推理服务 | 运行时威胁 | 隐私推断、成员推断、模型提取攻击 |
攻击者会选成本最低的阶段下手。用公开数据集训练的小模型,投毒最容易;部署在云端的大模型,查询接口才是主要攻击面。
| 能力等级 | 攻击者知道什么 | 典型攻击方法 | 攻击难度 |
|---|---|---|---|
| 白盒 | 模型结构、参数、训练数据 | FGSM、PGD、C&W | 最低 |
| 灰盒 | 模型结构、部分参数 | 迁移攻击、替代模型 | 中等 |
| 黑盒 | 只能查询模型获得输出 | NES、基于评分的攻击 | 较高 |
| 无交互 | 只能在训练前污染数据 | 数据投毒、后门植入 | 取决于数据管控 |
两个维度交叉后可以定位具体威胁场景。下表把前三篇的内容和本篇新增部分串在一起:
| 攻击阶段 | 攻击者能力 | 攻击方法 | 本系列覆盖 |
|---|---|---|---|
| 推理阶段 | 白盒 | FGSM / PGD / C&W | 第二篇:详细实验 |
| 推理阶段 | 黑盒 | NES / 迁移攻击 | 第二篇:原理介绍 |
| 推理阶段 | -- | 输入预处理防御 | 第二篇:中值滤波/位深度缩减 |
| 训练阶段 | 无交互 | 标签翻转投毒 | 第三篇:详细实验 |
| 训练阶段 | 无交互 | 后门攻击 | 第三篇:BadNets 实验 |
| 训练阶段 | -- | 后门检测防御 | 第三篇:Neural Cleanse/STRIP |
| 数据层 | 无交互 | 数据供应链攻击 | 本篇:扩展讨论 |
| 系统层 | 黑盒 | 隐私/成员推断 | 本篇:扩展讨论 |
| 全链路 | -- | 纵深防御体系 | 本篇:核心内容 |
纵深防御(Defense in Depth)的核心原则是不依赖任何单一防线,让攻击者每突破一层都要付出额外代价。AI 系统的防御可以分为四层:数据层、模型层、推理层、系统层。
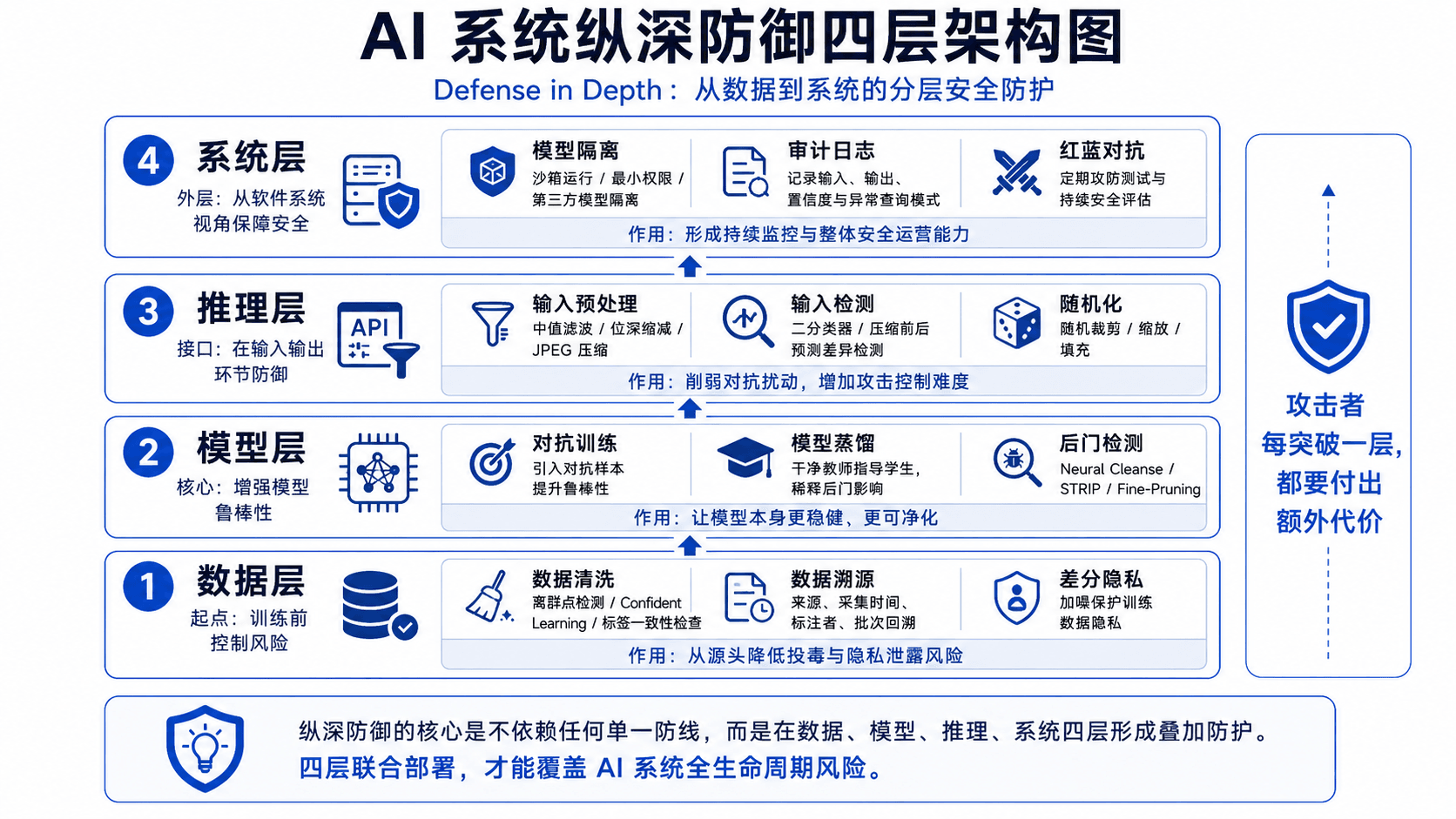
数据层是整条链路的起点。
数据清洗是最基础的手段。第三篇中我们看到,仅翻转 10% 的标签就能让模型准确率大幅下降。反过来,训练前识别出异常标签就能从源头消解投毒。常用方法:统计特征分布检测离群点;置信学习(Confident Learning)找标签可能有误的样本;交叉验证检查标签一致性。
数据溯源解决"这条数据从哪来"的问题。训练数据来自多个源头(爬虫、众包标注、第三方数据集)时,记录每条数据的来源、采集时间、标注者信息,模型行为异常时可以回溯到可疑批次。
差分隐私(Differential Privacy)目标不同——不防投毒,而是保护训练数据隐私。在数据中加入数学设计的噪声,使攻击者无法通过模型输出推断某条具体样本是否参与了训练。医疗、金融等敏感场景尤为重要。
模型层防御的目标是让模型本身更鲁棒。
对抗训练(Adversarial Training)目前是提升对抗鲁棒性最有效的方法。训练过程中不断生成对抗样本,让模型同时学习识别正常样本和对抗样本。代价是训练成本大幅增加,正常样本准确率通常会下降。
模型蒸馏(Model Distillation)可以用来"净化"可能被植入后门的模型。用干净的教师模型指导学生模型训练,学生模型学的是教师的输出分布而非原始训练数据,后门触发器和投毒效果在蒸馏过程中可能被稀释。
后门检测在第三篇已有介绍。Neural Cleanse 逆向工程寻找触发器,STRIP 通过叠加扰动检测可疑输入,Fine-Pruning 通过剪枝休眠神经元移除后门。三种方法各有适用场景。
推理层防御不修改模型本身,在输入输出环节做文章。
输入预处理在第二篇做过详细实验。中值滤波、位深度缩减、JPEG 压缩——本质是通过变换破坏对抗扰动的精细结构。优点是实现简单、与模型解耦;缺点是面对自适应攻击效果会大幅下降。
输入检测在样本送入模型前判断是否正常。可以训练二分类器区分正常样本和对抗样本;也可以用特征压缩方法,比较压缩前后模型预测的差异——差异过大说明样本可能被篡改。
随机化成本低但效果不错。推理时对输入施加随机变换(随机裁剪、缩放、填充),使攻击者难以精确控制扰动效果。对抗样本的构造依赖确定性梯度计算,随机性会显著增加攻击难度。
系统层防御跳出模型视角,从整个软件系统角度考虑安全。
模型隔离:在沙箱环境中运行模型推理,限制对文件系统、网络、内存的访问权限。和传统的最小权限原则一致。特别是第三方模型,隔离运行可以防止暗藏的恶意行为。
审计日志:记录每次输入、输出及预测置信度分布。异常模式(大量低置信度预测、短时间内大量相似查询)可作为攻击的早期预警。
红蓝对抗:定期用最新攻击方法测试模型鲁棒性。不仅发现具体漏洞,更重要的是建立持续的安全评估机制。
| 方法 | 防御层 | 防御对象 | 优点 | 局限 |
|---|---|---|---|---|
| 中值滤波 | 推理层 | 对抗样本 | 实现简单,即插即用 | 强攻击(如 C&W)下几乎失效 |
| 位深度缩减 | 推理层 | 对抗样本 | 计算开销极低 | 会损失图像细节信息 |
| JPEG 压缩 | 推理层 | 对抗样本 | 工程中容易集成 | 攻击者可针对性绕过 |
| 随机化变换 | 推理层 | 对抗样本 | 增加攻击不确定性 | 影响推理一致性 |
| 对抗训练 | 模型层 | 对抗样本 | 从根本上提升鲁棒性 | 训练成本高,牺牲正常准确率 |
| 模型蒸馏 | 模型层 | 后门/投毒 | 可净化可疑模型 | 需要可信的教师模型或数据 |
| Neural Cleanse | 模型层 | 后门攻击 | 能逆向工程出触发器 | 计算开销大,假设触发器较小 |
| STRIP | 推理层 | 后门攻击 | 可在线实时检测 | 需要干净的参考样本集 |
| Fine-Pruning | 模型层 | 后门攻击 | 可移除后门神经元 | 可能影响正常性能 |
| 数据清洗 | 数据层 | 数据投毒 | 源头防御 | 检测率有限,高级投毒难识别 |
| 差分隐私 | 数据层 | 隐私推断 | 有数学隐私保证 | 加噪声会降低模型精度 |
| 审计日志 | 系统层 | 多种攻击 | 支持事后追溯 | 无法实时阻止攻击 |
两个规律值得注意:
没有银弹。 每种方法都有明确的适用边界和局限性,单独依赖任何一种方法都不够。
安全和性能存在 trade-off。 对抗训练提升鲁棒性但降低正常准确率;差分隐私保护隐私但损失模型精度;输入预处理消除扰动但也去掉有用信息。实际部署中需要根据场景权衡。
前述所有防御方法都是经验性的——可以在已知攻击上测试效果,但无法保证对未知攻击同样有效。可验证防御试图解决这个问题。
Randomized Smoothing(随机平滑)是目前最有代表性的方案。对输入加高斯噪声,多次采样取投票结果,通过统计分析给出数学保证:在 范数半径 以内的任何扰动都不会改变分类结果。这不依赖攻击者用什么方法,是真正攻击无关的防御。Cohen 等人在 ICML 2019 [1] 给出了理论基础。
代价也很明显:推理时需要数百次采样,计算成本高;保证的鲁棒半径往往较小,高维图像上实际防护范围有限。但它指出了一个重要方向——我们需要"在理论上可证明"而非仅仅"在实验中有效"的安全保障。
多个机构协作训练共享模型时(例如多家医院联合训练诊断模型),每个参与方只上传梯度更新而非原始数据。这保护了隐私,但也开放了新的攻击面:恶意参与方可以上传精心设计的梯度来投毒或植入后门。中心服务器无法直接审查各方数据,检测这类攻击比集中式训练更困难。
大语言模型带来了全新的安全挑战。越狱攻击(Jailbreak)通过精心设计的提示词绕过安全限制;提示注入(Prompt Injection)让攻击者通过用户输入控制模型行为。这些攻击和传统对抗样本在形式上相似——都是操纵输入诱导模型产生预期外的输出——但 LLM 的输入输出空间是离散的自然语言,传统基于梯度的攻防方法不能直接套用。
这可能是最容易被忽视但影响最深远的问题。从 Hugging Face 下载预训练模型,或使用第三方标注的数据集时,我们在信任一个复杂的供应链。预训练模型可能被植入后门,数据集可能被污染,甚至模型格式的解析代码都可能包含漏洞(如 pickle 反序列化攻击)。这与软件工程中的供应链安全问题本质相同,但 AI 供应链的安全基础设施还远不如传统软件成熟。
本系列使用的实验环境——MNIST 数据集、LeNet-5 模型、FGSM 和 PGD 攻击——在教学上概念清晰、结果直观,但与现实场景差距很大。
| 维度 | 实验环境 | 现实场景 |
|---|---|---|
| 图像 | 28x28 灰度,10 类 | 224x224+ 彩色,成百上千类 |
| 模型 | LeNet-5,<10 万参数 | 千万到数十亿参数 |
| 攻击 | 数字空间,精确梯度 | 物理世界,需克服距离/角度/光照/噪声 |
现实中的攻击往往发生在物理世界:交通标志上的贴纸让自动驾驶误识别,3D 打印的对抗物体在不同角度持续欺骗检测系统,对抗眼镜框骗过人脸识别。这些攻击比数字空间更难实施,但一旦成功,危害也更直接。
实际建议:
-
建立模型测试流水线:上线前不仅测试正常准确率,还要用标准对抗攻击方法(如 AutoAttack)测试鲁棒性,把对抗鲁棒性作为和准确率同等重要的指标。
-
数据供应链管理:记录每个数据集的来源、版本和哈希值。对外部数据抽样审计,不直接使用来路不明的数据。
-
模型版本控制和审计:像管理代码一样管理模型——版本控制、变更记录、权限管理,任何更新都应该可追溯。
-
异常检测和监控:监控生产环境中模型行为。异常的输入分布、突变的预测置信度、短时间大量查询,都可能预示攻击正在发生。
四篇文章走过了一条从基础到全局的路径:
- 第一篇:模型怎么学——梯度下降、反向传播、损失函数。
- 第二篇:攻击者怎么"反向"利用梯度——不优化模型参数,而是优化输入扰动,让模型犯错。
- 第三篇:攻击面从推理阶段扩展到训练阶段——投毒和后门证明了"数据即代码"。
- 第四篇:AI 安全不是某个单点技术的问题,而是需要数据层、模型层、推理层、系统层协同工作的系统工程。
三个贯穿全系列的观察:AI 安全和传统安全有共通之处,纵深防御、最小权限、供应链安全等概念可以直接借鉴;攻防是动态演进的,每种防御提出后都会有针对性的自适应攻击出现;安全和性能的 trade-off 在具体场景中需要找到合理平衡点。
[1] Cohen, J., Rosenfeld, E., & Kolter, J. Z. (2019). Certified Adversarial Robustness via Randomized Smoothing. ICML 2019.
[2] Biggio, B., & Roli, F. (2018). Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning. Pattern Recognition, 84, 317-331.
[3] Kumar, R. S. S., et al. (2020). Adversarial Machine Learning — Industry Perspectives. IEEE Security & Privacy (S&P) 2020.