

作者:陈诗宇 | 复旦大学"智能系统安全实践"课程 Week 9-11 实验
系列文章:(一)机器学习与神经网络基础 → (二)对抗样本攻击与防御 → (三)数据投毒与后门攻击 → (四)AI安全全景与纵深防御
数据投毒 (Data Poisoning) 和后门攻击 (Backdoor Attack) 都是训练时攻击——攻击者不碰模型参数,而是篡改训练数据。与测试时攻击(FGSM/PGD 等修改推理阶段的输入)相比,训练时攻击不需要知道模型结构,只要能影响训练数据就行。
| 维度 | 测试时攻击 (FGSM/PGD) | 训练时攻击 (投毒/后门) |
|---|---|---|
| 攻击时机 | 推理阶段 | 训练阶段 |
| 攻击对象 | 测试样本 | 训练数据 |
| 是否需模型参数 | 白盒需要,黑盒可不需要 | 不需要 |
| 隐蔽性 | 受扰动预算约束 | 取决于投毒策略 |
| 现实威胁场景 | 自动驾驶路牌、人脸识别 | 众包标注、公开数据集、预训练模型 |
现实中的攻击面比想象中大:众包标注平台上恶意标注者故意标错、公开数据集被注入后门样本、预训练模型供应链中植入木马权重。
标签翻转是最直接的数据投毒方式:改标签 ,不改输入 。图片还是那张图片,只是告诉模型"这是另一个类"。
- 攻击 A:随机翻转 50% 样本的标签,标签被随机重新赋值。
- 攻击 B:定向翻转,前 60% 的 "7" 改为 "3",引导模型把 7 认成 3。
- 攻击 C:集中投毒,前 50% 样本全部改为 "3"。

| 攻击策略 | 整体准确率 | label=3 准确率 | label=7 准确率 | 特点 |
|---|---|---|---|---|
| 无投毒 (baseline) | ~99% | ~99% | ~99% | — |
| 攻击 A: 随机翻转 50% | 96.00% | — | — | 破坏分散,影响有限 |
| 攻击 B: 7→3 定向 60% | 91.68% | 99.70% | 31.61% | 类别偏置严重 |
| 攻击 C: 全改为3 50% | 34.54% | 100.00% | 18.58% | 模型几乎只会预测 3 |
攻击 A 把错误标签均匀撒向所有类别,来自 10 个类的噪声互相抵消,模型仍然能从干净的 50% 数据中学到正确的边界,所以整体准确率还是比较高。
攻击 B 把破坏力聚焦到 7→3 这条路径上。模型反复看到"长得像 7 的图片被标注为 3",结果 label=7 的准确率从 99% 暴跌到 31.61%,而 label=3 反而飙升到 99.70%——大量 7 的样本也在帮 3 训练。
攻击 C 走极端:50% 的训练样本全部标注为 3,模型学到"遇事不决就猜 3"的偏见,整体准确率直接塌到 34.54%。
结论:投毒方向越集中,破坏力越大。
攻击 B 的关键实现:
count = 0 total_7 = sum(1 for _, y in dataset if y == 7) limit = int(total_7 * 0.6) for i, (x, y) in enumerate(dataset): if y == 7 and count < limit: dataset.targets[i] = 3 count += 1
输入篡改换一个角度:改输入 ,不改标签 。给图片加噪声,但保留正确标签。
对所有训练样本注入均匀随机噪声 ,即在每个像素上加一个 范围的随机值,截断到 。
noise = torch.empty_like(x).uniform_(-eps, eps) x_noisy = torch.clamp(x + noise, 0.0, 1.0)
| 噪声强度 | 测试准确率 |
|---|---|
| 0.3 | 98.20% |
| 0.6 | 97.84% |
| 0.9 | 97.25% |
即使 (几乎覆盖了整个像素范围),准确率也只下降了不到 2%。MNIST 的特征太强了——黑底白字的笔画结构是决定性特征,均匀随机噪声不改变笔画的整体形状,模型仍然能提取关键的拓扑信息。换成特征更精细的数据集(CIFAR-10、ImageNet),效果会显著不同。更有效的做法是对抗性投毒——针对决策边界构造特定扰动,而非盲目加噪。
后门攻击 (Backdoor Attack) 在训练数据中植入隐藏行为:模型在干净输入上正常工作,但输入中出现特定 trigger pattern 时,输出攻击者指定的目标类。与数据投毒降低整体性能不同,后门攻击追求的是隐蔽的精准控制。
- Trigger pattern(触发器):贴在图片上的固定小图案。本实验用右下角 3×3 的白色方块。
- Target label(目标类):触发器激活后模型输出的类别。本实验为 3。
- Poisoning ratio(投毒比例):训练集中被植入后门的样本比例。

训练阶段(植入后门) 测试阶段(触发后门)
======================== ========================
训练集 干净输入
| |
v v
以 ratio 概率 +---> 模型 ---> 正确预测 (ACC)
选中样本 |
| 带 trigger
v 的输入
+--------+ |
| 贴上 | v
| trigger|---> 改标签为 target 模型 ---> 预测为 target (ASR)
| 3x3白块|
+--------+
|
v
混入训练集 ---> 正常训练
核心实现就三步:选样本、贴 trigger、改标签。
def backdoor_dataset(dataset, trigger, target, ratio): n = len(dataset) indices = random.sample(range(n), int(n * ratio)) for i in indices: x, _ = dataset[i] # 右下角贴 3x3 白色 trigger x[:, -3:, -3:] = 1.0 dataset.data[i] = x dataset.targets[i] = target return dataset
- ACC (Accuracy):干净测试集上的准确率。ACC 越高,后门越隐蔽。
- ASR (Attack Success Rate):带 trigger 的测试样本被预测为 target 的比例。ASR 越高,攻击越成功。
理想的后门攻击:ACC 干净模型的准确率,ASR 100%。
参考文献:Gu et al., "BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain", 2017。首次系统性地提出神经网络后门攻击框架。
后门攻击需要污染多少数据才能生效?
| 投毒比例 (ratio) | ACC (干净样本) | ASR (后门样本) |
|---|---|---|
| 1% | 98.35% | 99.63% |
| 5% | 98.14% | 99.95% |
| 10% | 98.06% | 99.95% |
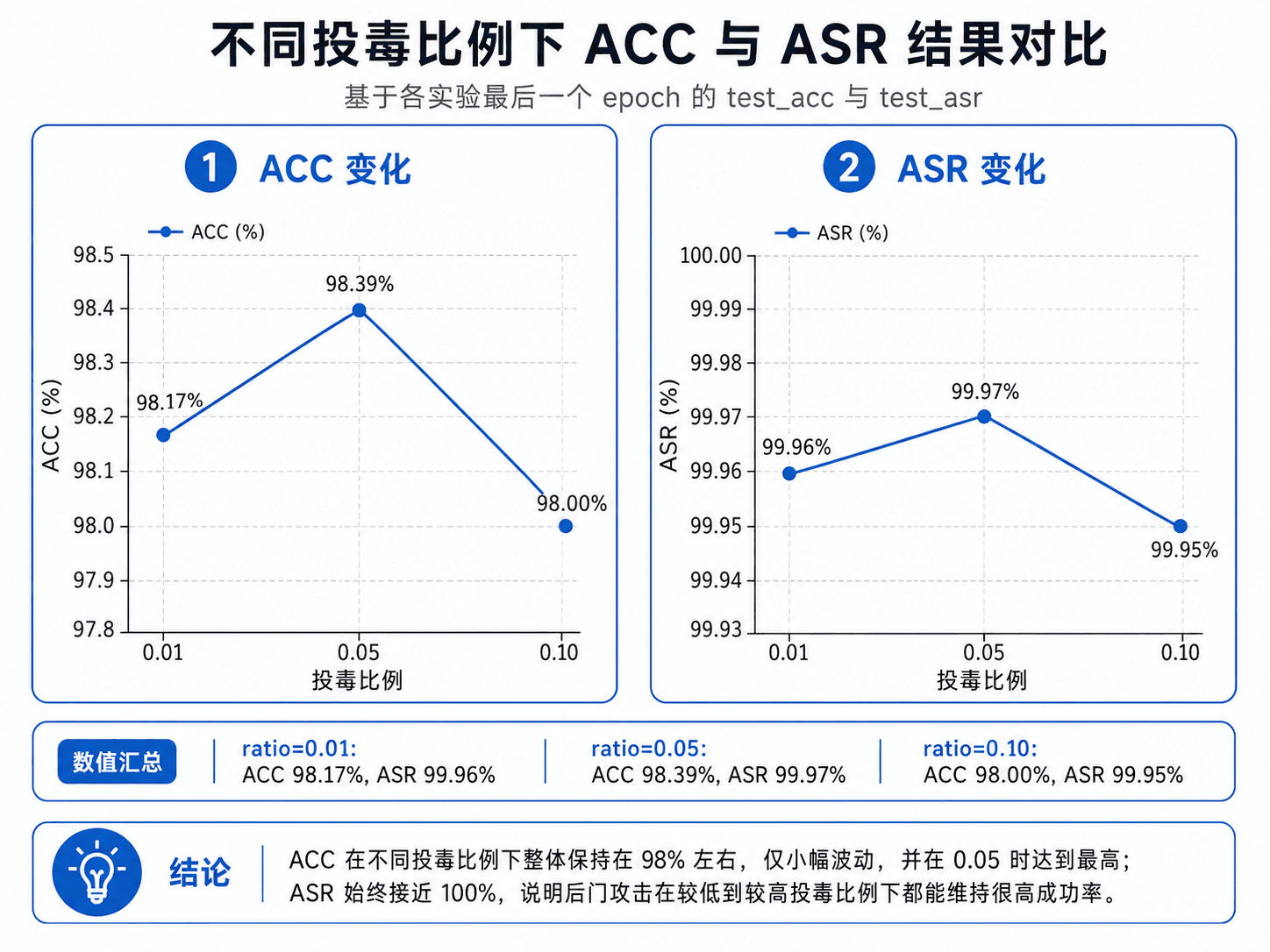
仅污染 1% 的训练数据(60000 张中的 600 张),就能达到 99.63% 的攻击成功率,同时保持 98.35% 的干净准确率。ACC 只下降了不到 1 个百分点,常规测试根本发现不了异常。但任何带有右下角 3×3 白块的输入都会被预测为 3。
随着 ratio 从 1% 增加到 10%,ASR 从 99.63% 提升到 99.95%(接近饱和),ACC 仅微降到 98.06%。后门攻击对投毒比例的效率极高。
| 维度 | 数据投毒 | 后门攻击 |
|---|---|---|
| 攻击目标 | 降低整体性能 | 植入隐藏后门 |
| 对正常任务的影响 | 性能明显下降 | 几乎无影响 |
| 触发条件 | 无(始终生效) | 需要特定 trigger |
| 攻击者控制力 | 低(只能破坏) | 高(精准控制目标类) |
| 隐蔽性 | 低(性能下降可被发现) | 高(常规测试无法检出) |
| 最低投毒量 | 通常需要较高比例 | 1% 即可生效 |
后门攻击的核心优势在于隐蔽性:模型通过了所有常规测试(ACC 正常),只有攻击者知道如何触发后门。在预训练模型下载、第三方 API 调用、联邦学习等 AI 模型供应链场景中,这种攻击尤其危险。
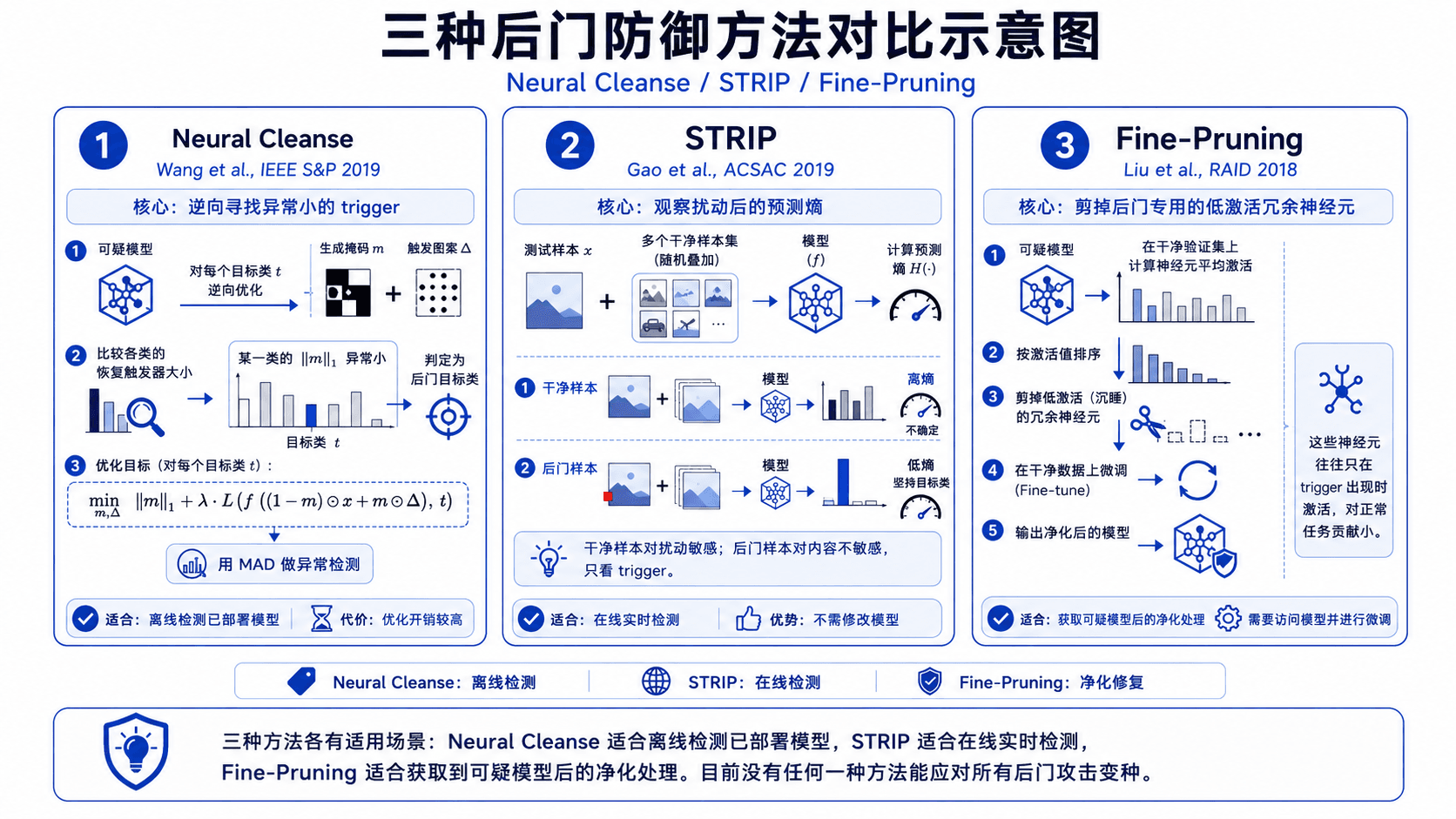
后门攻击的隐蔽性使得防御成为一个开放性难题。目前有三类主流方法。
Neural Cleanse 的思路是:如果模型存在后门,那么存在一个特别"小"的扰动,能把所有类别的输入都翻转为后门目标类。对每个类 ,通过优化求解 ,其中 是 mask、 是 trigger pattern。如果某个类 对应的最优 异常地小(用 MAD 异常检测),就判定该类是后门目标类。
Wang et al., "Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks", IEEE S&P 2019

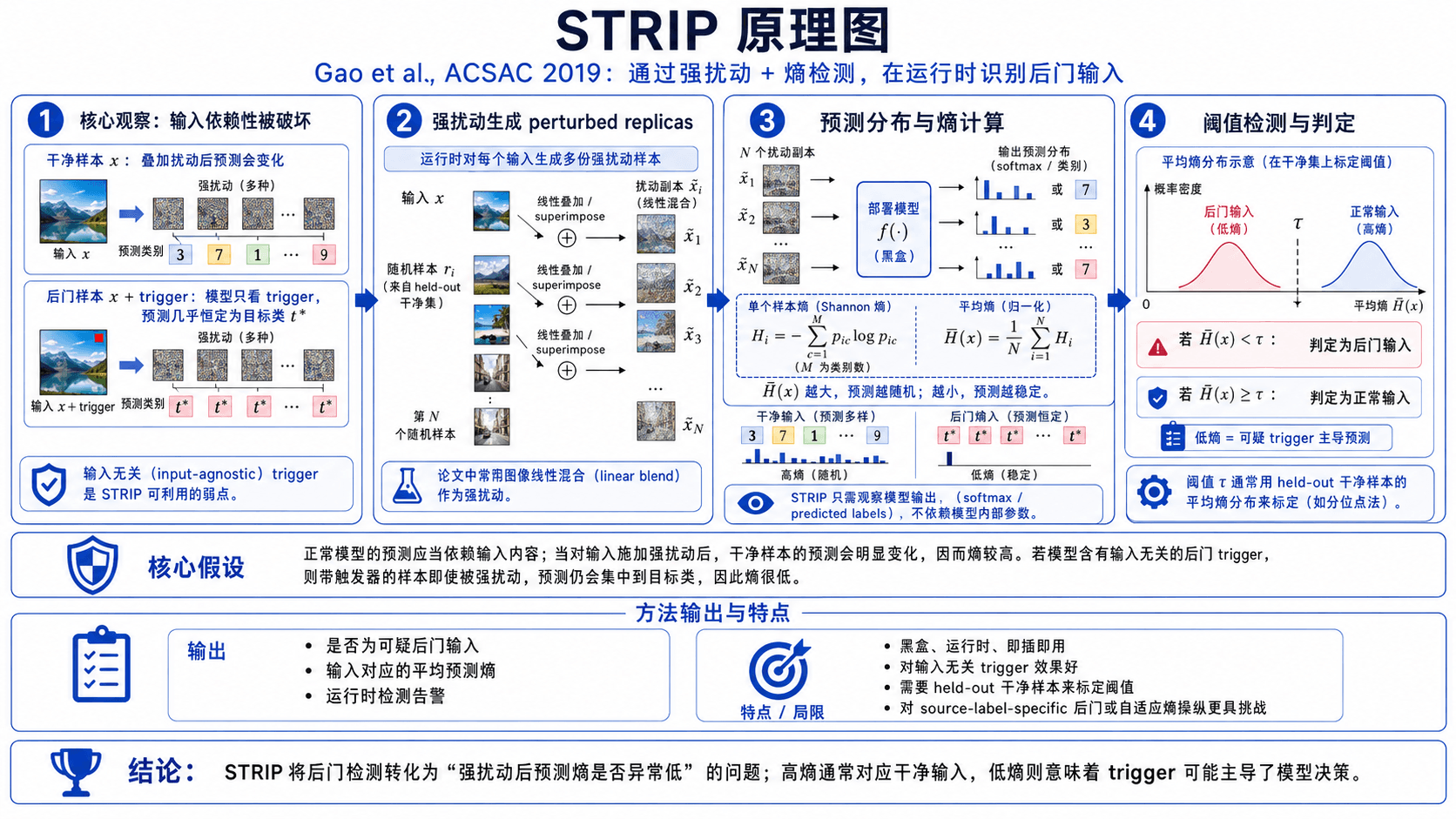
STRIP 利用的是:干净样本的预测对输入扰动敏感(加噪声后预测会变),而后门样本不敏感(模型只看 trigger,不看内容)。具体做法是把测试样本和随机样本叠加,观察预测分布的熵。干净样本叠加后熵较高(预测不确定),后门样本叠加后熵仍然很低(模型坚持预测为目标类)。
Gao et al., "STRIP: A Defence Against Trojan Attacks on Deep Neural Networks", ACSAC 2019
Fine-Pruning 认为后门行为依赖于模型中某些"冗余"神经元——它们只在 trigger 出现时激活,对正常任务没有贡献。做法是按神经元在干净验证集上的平均激活值排序,剪掉激活值最低的那些(它们大概率是后门专用的),然后微调恢复正常性能。
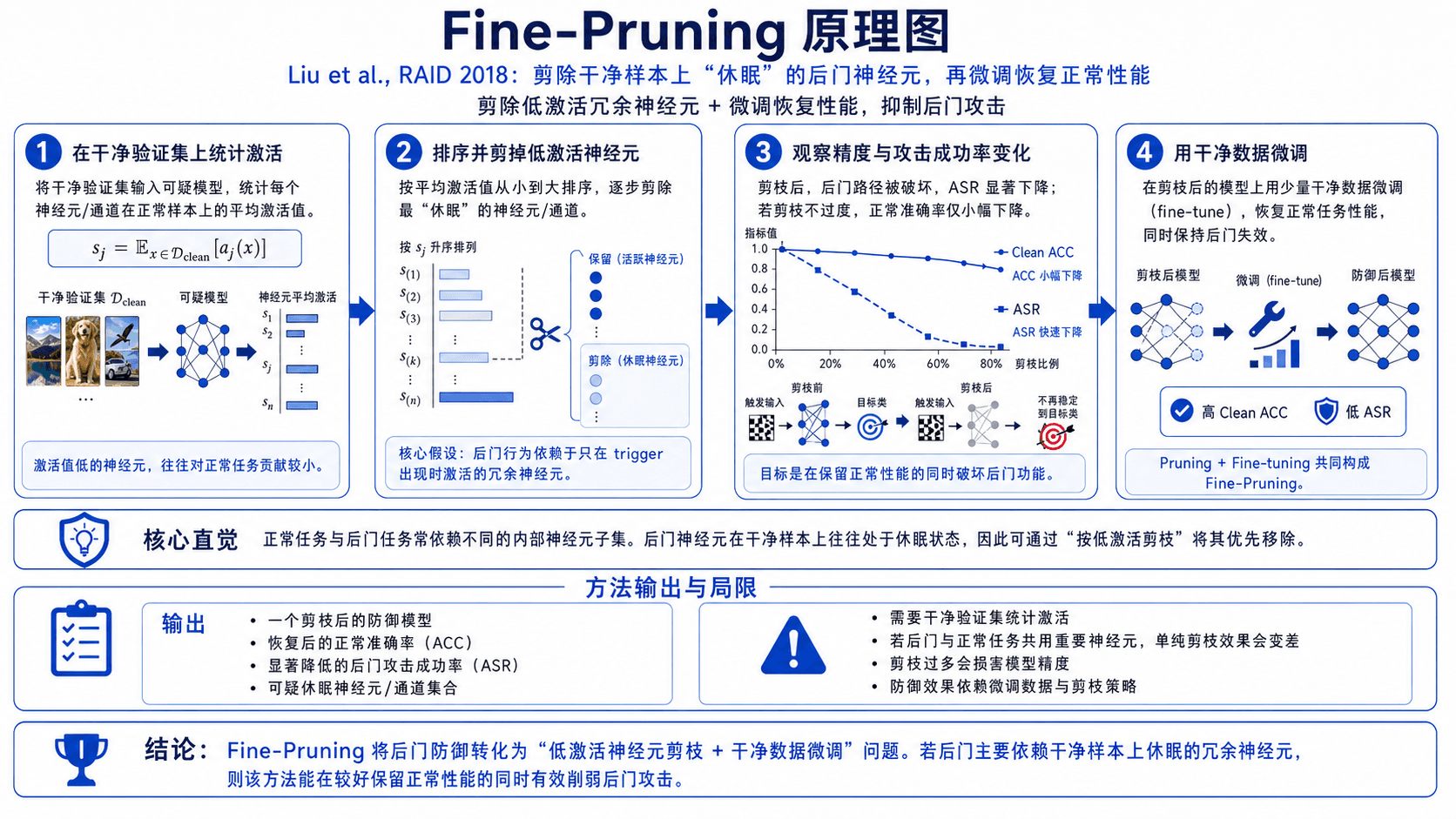
Liu et al., "Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks", RAID 2018
三种方法各有适用场景:Neural Cleanse 适合离线检测已部署模型,STRIP 适合在线实时检测,Fine-Pruning 适合获取到可疑模型后的净化处理。目前没有任何一种方法能应对所有后门攻击变种。
标签翻转揭示了投毒的基本规律:方向越集中,破坏力越大。输入篡改在 MNIST 上效果不佳,提醒我们投毒效果依赖于数据集特征的复杂度。后门攻击是训练时攻击中威胁最大的形态——仅 1% 的投毒率就能植入几乎完美的后门,同时不影响正常性能,常规测试完全无法发现异常。
与测试时攻击相比,训练时攻击更难防范。测试时攻击可以通过对抗训练增强鲁棒性;训练时攻击的根源在于数据来源不可控,而现代深度学习恰恰高度依赖大规模、多来源的训练数据。后门攻击对 AI 供应链安全构成了系统性威胁,毕竟当你从网上下载一个预训练模型时,你并不知道它里面有没有后门。
上一节的后门攻击有一个明显弱点:trigger 是右下角的白色方块,肉眼一看就知道图片被动过手脚。不可见后门攻击解决了这个问题——trigger 变成覆盖整张图片的微小噪声,视觉上与干净样本无异。
| 维度 | 可见后门 | 不可见后门 |
|---|---|---|
| Trigger 形式 | 局部补丁(固定白色方块) | 全局噪声(覆盖整张图片) |
| Trigger 生成 | 预先固定 | 训练过程中联合优化 |
| 可见性 | 肉眼可见 | 肉眼不可见(L2 正则约束) |
| 隐蔽性 | 中等 | 高 |
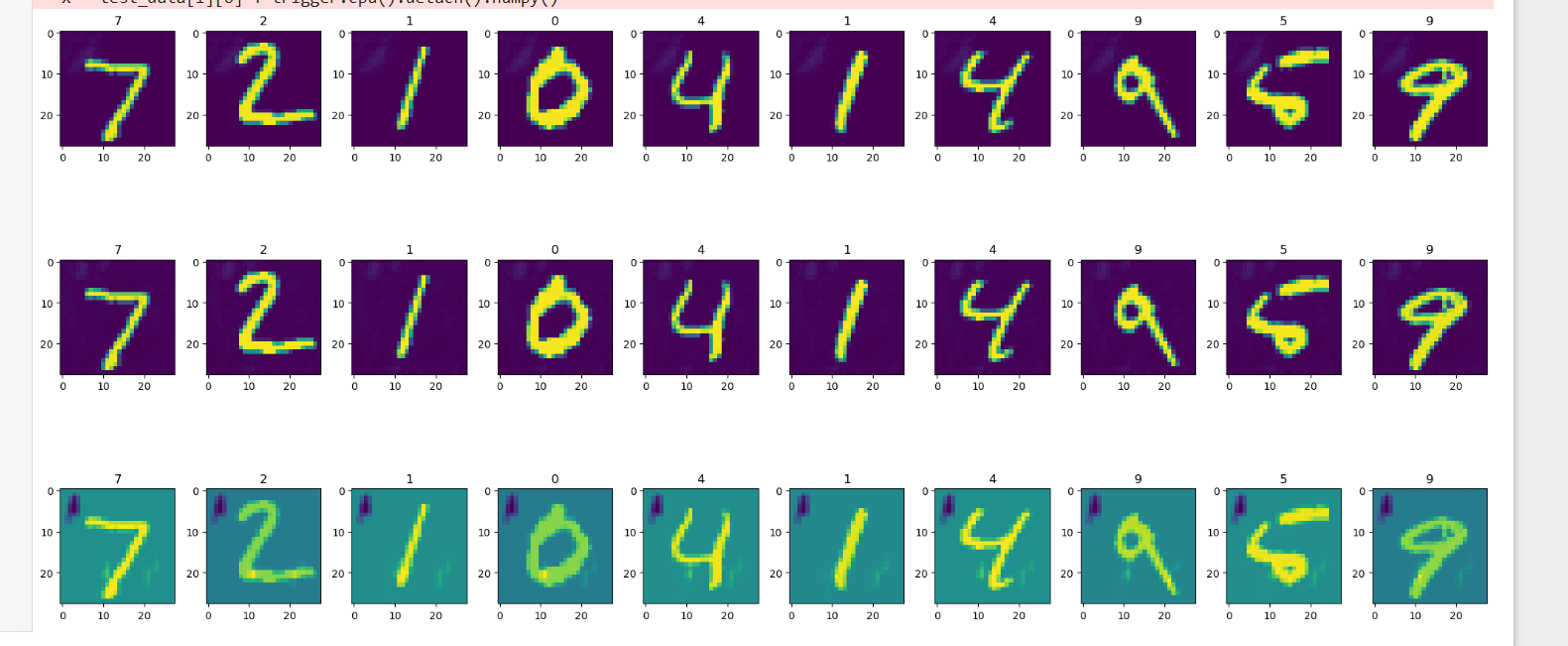
不可见后门的关键在于 trigger 本身是一个可学习参数,和模型参数一起通过梯度下降优化:
trigger = torch.rand(28, 28) trigger.requires_grad = True optim_trigger = Adam([trigger], lr=trigger_lr)
训练时的总损失由三部分组成:
total_loss = main_loss + 0.5 * backdoor_loss + 0.1 * reg_loss
| Loss | 计算方式 | 作用 |
|---|---|---|
| main_loss | CE(model(x), y) | 保证干净样本分类正常 |
| backdoor_loss | CE(model(x + trigger), target) | 植入后门行为 |
| reg_loss | ‖trigger‖₂ | 约束 trigger 幅度,保持不可见 |
每个 batch 中,梯度同时流向模型参数和 trigger,分别由两个优化器更新。reg_loss 的权重(0.1)控制了隐蔽性和攻击效果之间的平衡——权重越大 trigger 越小越隐蔽,但后门可能不够强。
在 MNIST + LeNet5 上,不同 trigger 学习率的效果:
| trigger_lr | ACC | ASR |
|---|---|---|
| 0.005 | 98.04% | 100.00% |
| 0.01 | 98.45% | 100.00% |
| 0.05 | 98.40% | 100.00% |
三种学习率下 ASR 都达到了 100%,ACC 保持在 98% 以上。trigger_lr 主要影响 trigger 的收敛速度和最终幅度,对攻击成功率影响不大。
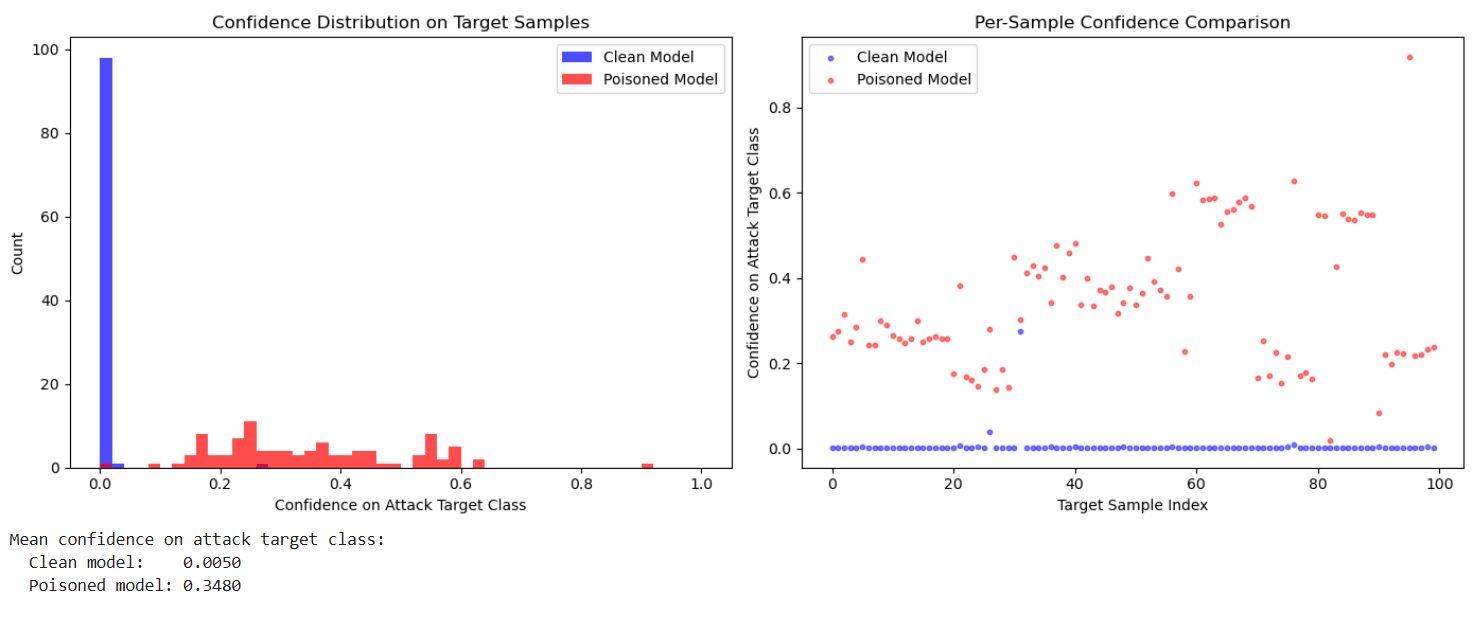
不可见后门解决了 trigger 的可见性问题,但投毒样本的标签仍然被改为 target——如果有人逐条检查标签,还是能发现"图片是猫但标签是狗"的异常。Clean-Label Attack 更进一步:投毒样本的标签完全正确,攻击者只修改像素内容。
模型的分类依赖特征空间中的决策边界。Clean-Label Attack 的策略是:优化投毒样本的像素,使其在特征空间中靠近目标样本,但标签保持为原始类别。当模型在这些投毒样本上微调时,决策边界被扭曲,目标样本就会被错误分类。
攻击流程:
1. 选择目标样本 t(测试集中要被攻击的样本)
2. 选择基础样本 b(训练集中与目标不同类的样本)
3. 优化 b 的像素 → 使 f(b) 接近 f(t),但标签不变
4. 将优化后的样本放入训练集
5. 微调模型 → 决策边界被扭曲 → 目标样本被错误分类
# p: 投毒样本(初始化为基础样本 b) # t: 目标样本 # f: 特征提取器(模型倒数第二层输出) p = b.clone().requires_grad_(True) for i in range(iters): loss = (f(p) - f(t)).pow(2).sum() + beta * (p - b).pow(2).sum() loss.backward() p = (p - lr * p.grad).clamp(0, 1).detach().requires_grad_(True)
两个 loss 项:
‖f(p) - f(t)‖²:特征碰撞,让投毒样本的特征靠近目标β·‖p - b‖²:视觉约束,让投毒样本看起来还像原来的基础样本
Clean-Label Attack 要求微调时冻结特征提取器,只更新最后的全连接层。原因是:投毒样本的特征碰撞是在固定特征空间中完成的,如果特征提取器也被更新,特征空间会变化,碰撞效果就失效了。
在 CIFAR-10 + ResNet-18 上:
| 指标 | 值 |
|---|---|
| 微调后 ACC | ~80% |
| 攻击成功率 ASR | ~14% |
ASR 只有 14%,远低于可见后门的 99%+。这说明 Clean-Label Attack 的攻击效果有限,但它的价值在于极高的隐蔽性——标签完全正确,任何数据审查都无法通过标签异常来发现投毒样本。
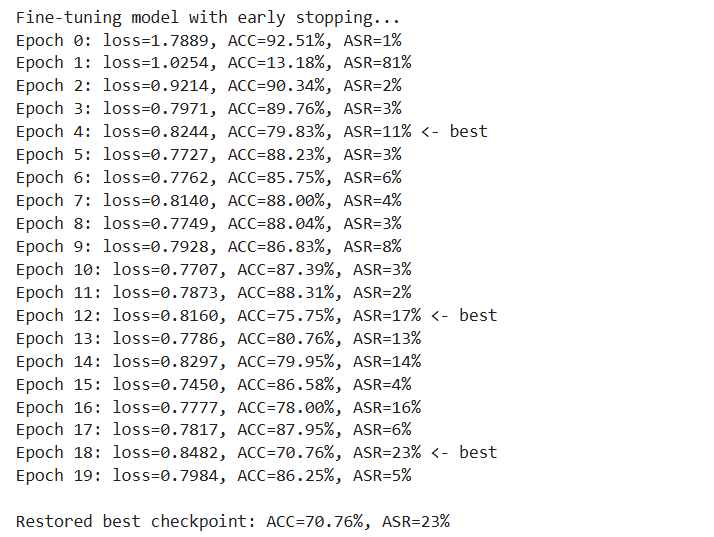

直方图与逐样本对比
| 阶段 | 方法 | Trigger | 标签 | 隐蔽性 |
|---|---|---|---|---|
| Week10 | BadNets | 可见补丁 | 改为 target | 低 |
| Week11 | 不可见后门 | 全局噪声(L2约束) | 改为 target | 中高 |
| Week11 | Clean-Label | 特征碰撞扰动 | 不改(正确标签) | 极高 |
标签翻转揭示了投毒的基本规律:方向越集中,破坏力越大。输入篡改在 MNIST 上效果不佳,提醒我们投毒效果依赖于数据集特征的复杂度。后门攻击是训练时攻击中威胁最大的形态——仅 1% 的投毒率就能植入几乎完美的后门,同时不影响正常性能,常规测试完全无法发现异常。
不可见后门和 Clean-Label Attack 代表了后门攻击的两个进化方向:前者让 trigger 不可见,后者让标签不可疑。两者结合意味着投毒样本在视觉和标签两个维度上都无法被简单检测,这对 AI 供应链安全构成了更严峻的挑战。
- Gu, T., Dolan-Gavitt, B., & Garg, S. (2017). BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. arXiv:1708.06733.
- Shafahi, A., et al. (2018). Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks. NeurIPS.
- Wang, B., et al. (2019). Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. IEEE S&P.
- Gao, Y., et al. (2019). STRIP: A Defence Against Trojan Attacks on Deep Neural Networks. ACSAC.
- Liu, K., Dolan-Gavitt, B., & Garg, S. (2018). Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. RAID.