

系列:AI安全:从机器学习基础、投毒攻击到纵深防御
作者:陈诗宇 | 复旦大学"智能系统安全实践"课程 Week 5-7 实验
实验环境:LeNet-5 / MNIST / PyTorch
对抗样本(adversarial examples)是在原始输入上添加人眼不可察觉的扰动,使模型产生错误输出的构造性输入。Goodfellow 等人 2015 年的经典示例:一张熊猫图片加上微小噪声后,模型以 99.3% 的信心判定为长臂猿。

正常训练和对抗攻击做的事情恰好相反。正常训练是最小化损失函数来调整模型参数:
对抗攻击则是固定模型参数,最大化损失函数来构造输入扰动:
约束保证每个像素最多改 。(像素值归一化到 [0,1])时扰动肉眼还能接受。优化对象不同(参数 vs 输入),优化方向不同(最小化 vs 最大化),但数学工具是同一套——梯度。
FGSM(Fast Gradient Sign Method, Goodfellow 2015)对输入求损失函数的梯度,取符号后沿梯度方向走一步 :
取 sign 而不是直接用梯度值,是因为梯度各维度大小差异很大,直接用无法满足 的约束。取 sign 后每个像素要么 要么 ,刚好顶到约束边界。
完整实现只有五行:
x.requires_grad = True loss = F.cross_entropy(model(x), y) loss.backward() x_adv = x + eps * x.grad.sign() x_adv = x_adv.clamp(0, 1)
clamp(0, 1) 保证生成的图片仍在合法像素范围内。
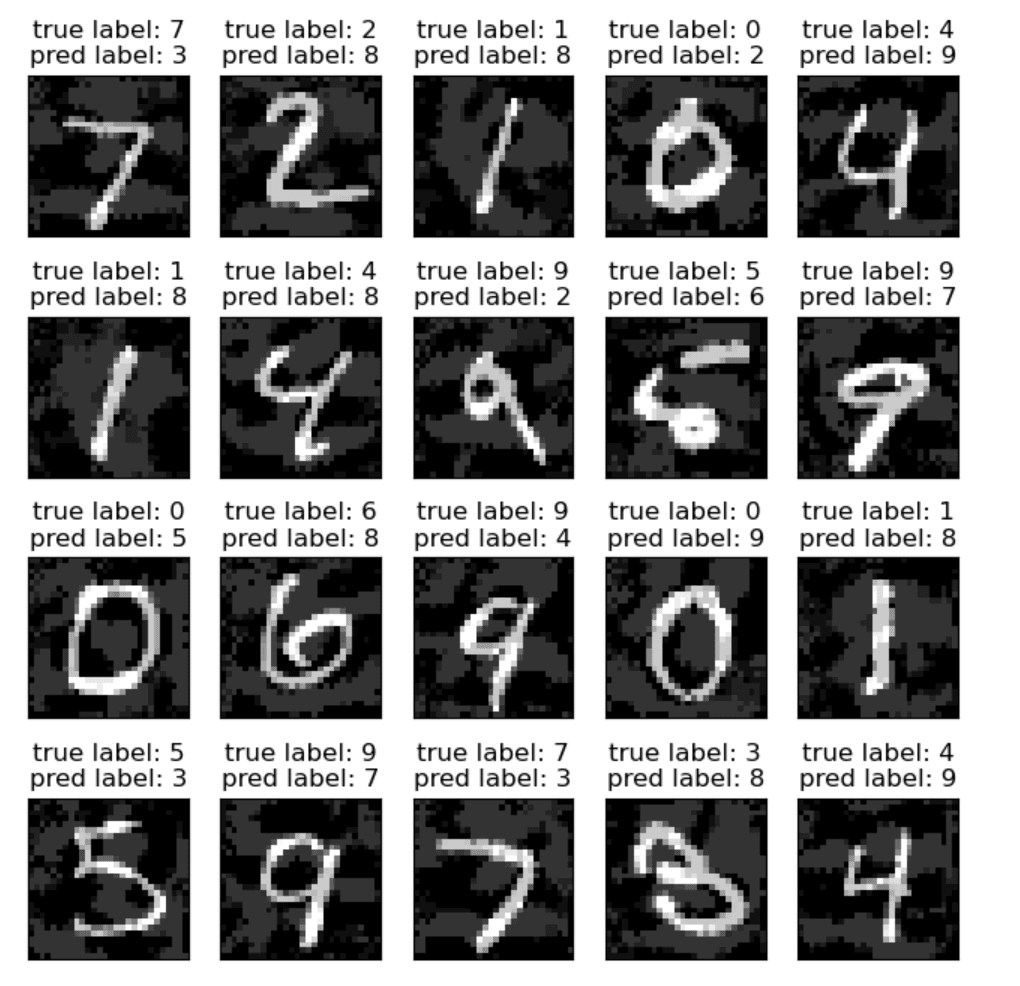
实验结果: 时,match rate = 0.15。只有 15% 的样本还能被正确分类,一步扰动就让准确率从 97% 暴跌到 15%。
攻击前:

攻击后:
FGSM 只走一步,未必找到 -球内的最优扰动。PGD(Projected Gradient Descent, Madry et al. 2018)多走几步,每步走小一点,走出球就投影回来:
是投影操作,。投影的实现就是一行 clamp:delta = torch.clamp(x_adv - x, -eps, eps)。
| 维度 | FGSM | PGD |
|---|---|---|
| 步数 | 1 步 | 多步迭代(通常 5-40) |
| 步长 | (一步到位) | (小步前进) |
| 约束处理 | sign 天然满足 | 每步投影回 -球 |
| 攻击强度 | 较弱 | 更强 |
| 计算开销 | 1 次前向+反向 | 次前向+反向 |
完整实现:
x_adv = x.detach().clone() for _ in range(num_iter): x_adv.requires_grad = True loss = F.cross_entropy(model(x_adv), y) loss.backward() with torch.no_grad(): x_adv = x_adv + alpha * x_adv.grad.sign() # 投影:确保扰动不超过 eps delta = torch.clamp(x_adv - x, -eps, eps) x_adv = torch.clamp(x + delta, 0, 1)
detach().clone() 断开与原始计算图的连接,在新张量上重新跟踪梯度。漏了这一步梯度会穿透到前面的计算,结果完全不对。
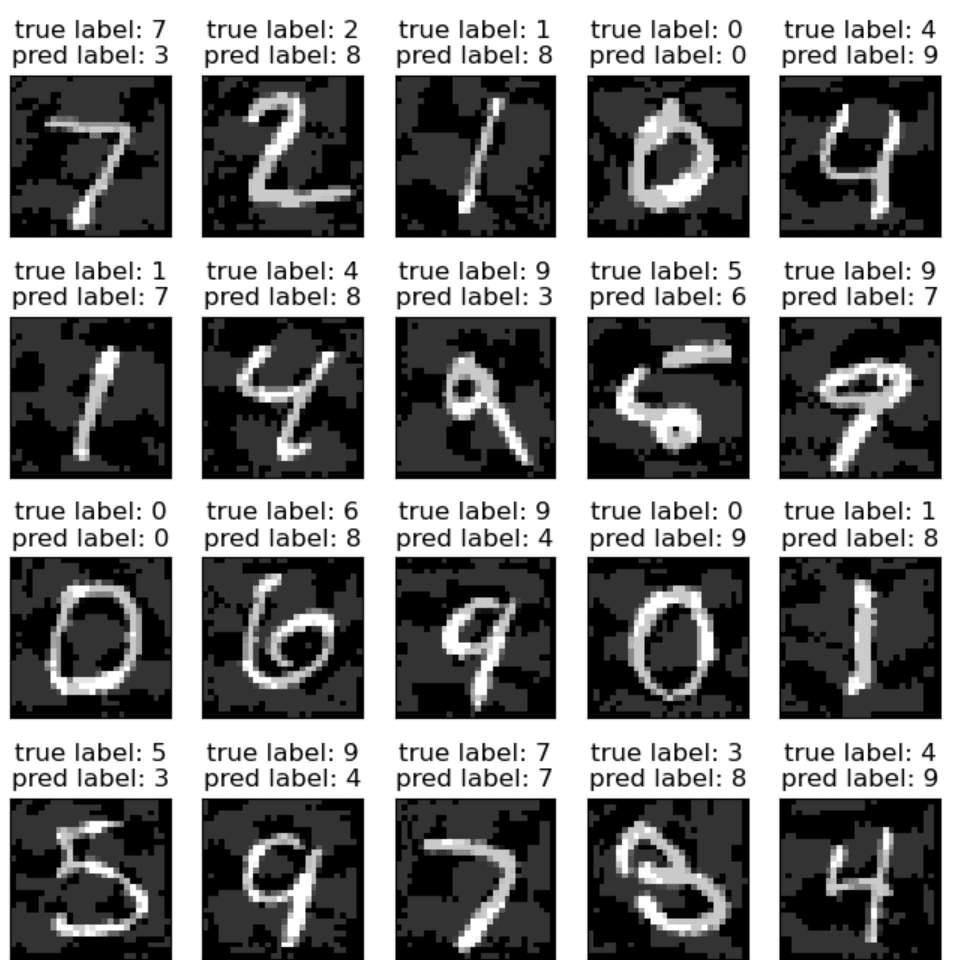
实验结果:, , 5 步迭代,match rate 降到 0.00-0.05。PGD 能把正确率打到接近零。
攻击后,可对比前面的一步FGSM攻击效果:
前面的攻击都是无目标的:让模型犯错就行。有目标攻击更进一步:让模型犯一个指定的错,比如把"3"识别成"7"。
数学上的区别只有一个符号:
- 无目标: — 沿梯度方向,让 loss 增大
- 有目标: — 沿梯度反方向,让对目标类 的 loss 减小
加变减,仅此而已。
实验结果:
| 攻击方式 | 方法 | 参数 | match rate / target match rate |
|---|---|---|---|
| 无目标 FGSM | +sign(grad) | match rate = 0.15 | |
| 有目标 FGSM | -sign(grad) | target match rate = 0.45 | |
| 无目标 PGD | 多步 +sign | , , 5步 | match rate = 0.00-0.05 |
| 有目标 PGD | 多步 -sign | , , 7步 | target match rate = 0.90 |
有目标比无目标更难——"推离正确答案"比"精确引导到目标类"容易得多。但 PGD 的多步迭代在有目标场景下也达到了 90% 的命中率,给足迭代次数和扰动空间,攻击者几乎可以随心所欲地控制模型输出。
有目标FGSM:

有目标PGD:

前面的攻击都是白盒的——攻击者能拿到模型参数来计算梯度。现实中攻击者面对的往往是一个 API:输入图片,返回预测,内部一无所知。
NES(Natural Evolution Strategies, Ilyas et al. 2018)用随机采样估计梯度:
从标准正态分布采样, 是采样步长。往 个随机方向各探测一下,看 loss 变化多少,综合得到梯度的近似值。这本质上是高维空间中沿随机方向做的有限差分法。
grad_est = torch.zeros_like(x) for _ in range(n): u = torch.randn_like(x) loss_plus = F.cross_entropy(model(x + sigma * u), y) loss_minus = F.cross_entropy(model(x - sigma * u), y) grad_est += (loss_plus - loss_minus) / (2 * sigma) * u grad_est /= n x_adv = x + eps * grad_est.sign()
实验结果:, , match rate = 0.70。

和白盒的 0.15(FGSM)或 0.00(PGD)比弱了不少,毕竟是估计出来的梯度。但黑盒攻击不需要任何模型内部信息,只要能查询模型输出就行——模型参数完全保密也挡不住。
中值滤波用 滑动窗口取中值替代中心像素,对脉冲噪声(孤立极端值)特别有效。对抗扰动中确实有不少像素被推到极端值。
把像素值量化到有限档位。depth=2 只保留 4 个灰度级(0, 85, 170, 255)。对抗扰动通常只有几个灰度级的幅度,量化后直接被抹平。
实验结果(, FGSM 攻击):
| 防御方法 | 参数 | 干净样本准确率 | FGSM 攻击后准确率 |
|---|---|---|---|
| 无防御 | — | 0.97 | 0.45 |
| 中值滤波 | ~0.95 | 0.50 | |
| 位深度缩减 | depth=2 | ~0.90 | 0.95 |
位深度缩减效果不错,准确率从 0.45 恢复到 0.95。但干净样本上掉了点准确率(0.97 → 0.90),因为量化本身丢失信息。面对大 或 PGD 等强攻击时效果也会急剧下降——强扰动跨越了量化边界,量化救不回来。
预处理防御的本质局限:没有改变模型本身。模型依然脆弱,只是在输入端加了一层滤网。如果攻击者知道你用了什么预处理(自适应攻击),可以把预处理包进优化过程里,照样攻破。

对抗训练(adversarial training)从根源下手:让模型在训练阶段就见过对抗样本。
先用 FGSM/PGD 对整个训练集生成对抗样本,然后把对抗样本和原始样本混在一起重新训练。
实现简单,但对抗样本是用旧模型生成的。随着训练进行模型在变,预先生成的对抗样本已经"过时"了——模型学会了应对旧的扰动,对新生成的对抗样本依然脆弱。
每个 batch 都用当前模型实时生成对抗样本,同时优化正常 loss 和对抗 loss:
for x, y in dataloader: # 实时生成对抗样本 x_adv = pgd_attack(model, x, y, eps, alpha, num_iter) # 计算混合 loss loss_benign = F.cross_entropy(model(x), y) loss_adv = F.cross_entropy(model(x_adv), y) loss = loss_benign + loss_adv optimizer.zero_grad() loss.backward() optimizer.step()
| 维度 | Two-Step | Iterative |
|---|---|---|
| 对抗样本生成时机 | 训练前一次性生成 | 每 batch 实时生成 |
| 与当前模型的匹配度 | 低(用旧模型生成) | 高(用当前模型生成) |
| 鲁棒性 | 一般 | 更强 |
| 训练耗时 | 与正常训练差不多 | 慢 倍( = PGD 步数) |
| 适用场景 | 快速获得基线鲁棒性 | 追求最强鲁棒性 |
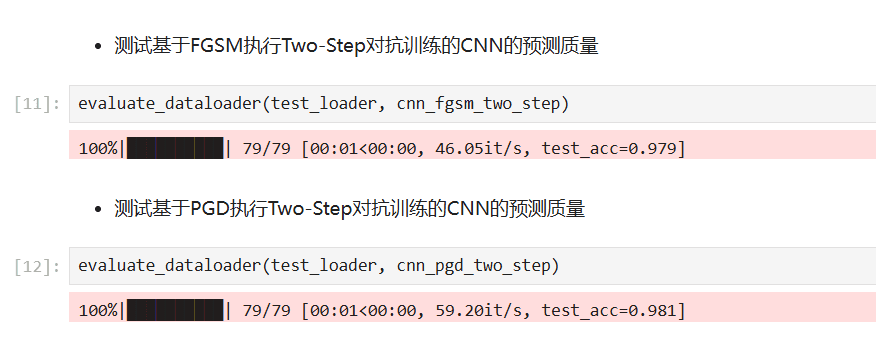
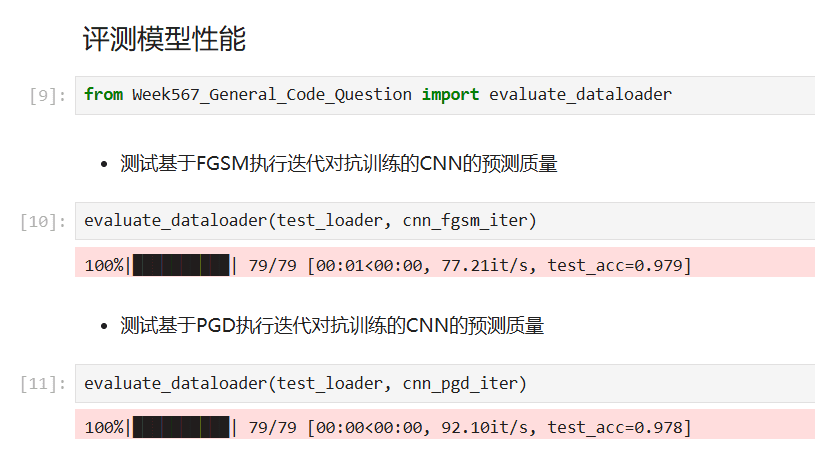
对抗训练后的模型面对 FGSM 和 PGD 攻击鲁棒性显著提升,不再被简单的梯度攻击轻易骗过。
| 类别 | 方法 | 核心思路 | 局限 |
|---|---|---|---|
| 白盒攻击 | FGSM | 一步梯度符号攻击 | 攻击强度有限 |
| 白盒攻击 | PGD | 多步迭代 + 投影 | 需要多次前向反向传播 |
| 黑盒攻击 | NES | 随机采样估计梯度 | 查询次数多,效果弱于白盒 |
| 预处理防御 | 中值滤波 / 位深度缩减 | 输入端去噪 | 不改变模型,自适应攻击可绕过 |
| 模型防御 | 对抗训练 | 训练时引入对抗样本 | 训练成本高,干净准确率略降 |
几个核心观察:
预处理治标,对抗训练治本。 预处理不改变模型决策边界;对抗训练直接改变 loss landscape,让决策边界对小扰动更不敏感。
鲁棒性有代价。 鲁棒模型通常在干净样本上损失几个百分点的准确率——这就是 accuracy-robustness trade-off。模型要同时应对正常输入和对抗输入,容量有限时只能牺牲一点正常准确率。
没有万能防御。 攻防是军备竞赛。自适应攻击(adaptive attacks)会把防御机制纳入优化目标,Tramer et al. 2020 的工作表明很多看似有效的防御在自适应攻击面前不堪一击。评估防御时必须用最强的攻击。
下一篇,攻击面从测试时转移到训练时——数据投毒和后门攻击。
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2015). Explaining and Harnessing Adversarial Examples. ICLR 2015.
- Madry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladu, A. (2018). Towards Deep Learning Models Resistant to Adversarial Attacks. ICLR 2018.
- Ilyas, A., Engstrom, L., Athalye, A., & Lin, J. (2018). Black-box Adversarial Attacks with Limited Queries and Information. ICML 2018.
- Xu, W., Evans, D., & Qi, Y. (2018). Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. NDSS 2018.