

作者:陈诗宇 | 复旦大学"智能系统安全实践"课程学习笔记
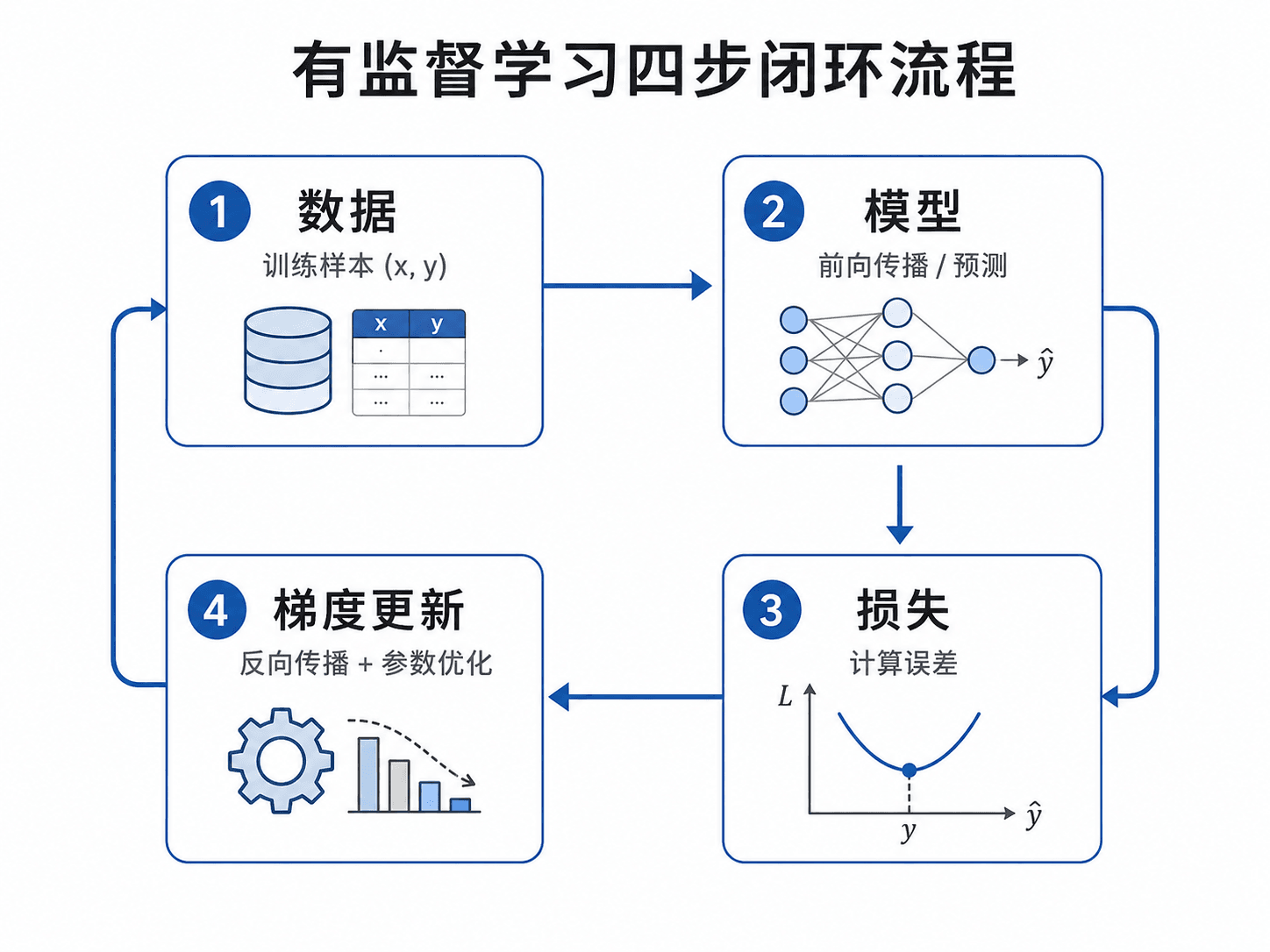
有监督学习是给模型大量带标签的数据 ,通过最小化预测与真实标签之间的损失来训练参数。训练流程是一个四步循环:前向传播算输出、计算损失、反向传播算梯度、更新参数。
以红酒分类为例:输入 13 个化学特征(酒精度、苹果酸含量等),输出 3 个产地类别。
模型最后一层输出的 logits 没有概率意义,Softmax 把它们变成概率分布:
对每个值取指数再归一化。[2.1, 0.5, -1.3] 变成 [0.82, 0.16, 0.02],模型认为这瓶酒 82% 的概率来自第一个产地。
有了预测概率 和真实标签 (one-hot),交叉熵损失衡量两者差距:
实际上只看真实类别对应的预测概率,取负对数。模型对正确类别给 0.99 的概率时 loss 接近 0;只给 0.01 时 loss 极大。这个函数对"自信地犯错"惩罚极重。
最小化 loss 的标准做法是梯度下降,即沿 loss 对参数的梯度反方向更新:
是学习率,控制步长。步子太大震荡,太小收敛慢。
这四步就是有监督学习的全部核心流程。后面所有内容都在这个框架上做文章。
线性模型 在特征空间里画超平面分割类别。但现实中分类边界往往不是线性的——MNIST 手写数字就是典型例子。线性模型在 MNIST 上准确率大约 80% 出头。
多层感知机(MLP)把多个线性层叠起来,中间插入非线性激活函数:
输入 x ──> [线性层1] ──> [激活函数] ──> [线性层2] ──> 输出
W1*x + b1 σ(·) W2*h + b2
没有激活函数时,两个线性层的叠加 仍然是线性变换,多层和单层没有区别。激活函数打破线性叠加,让网络能拟合曲线边界。
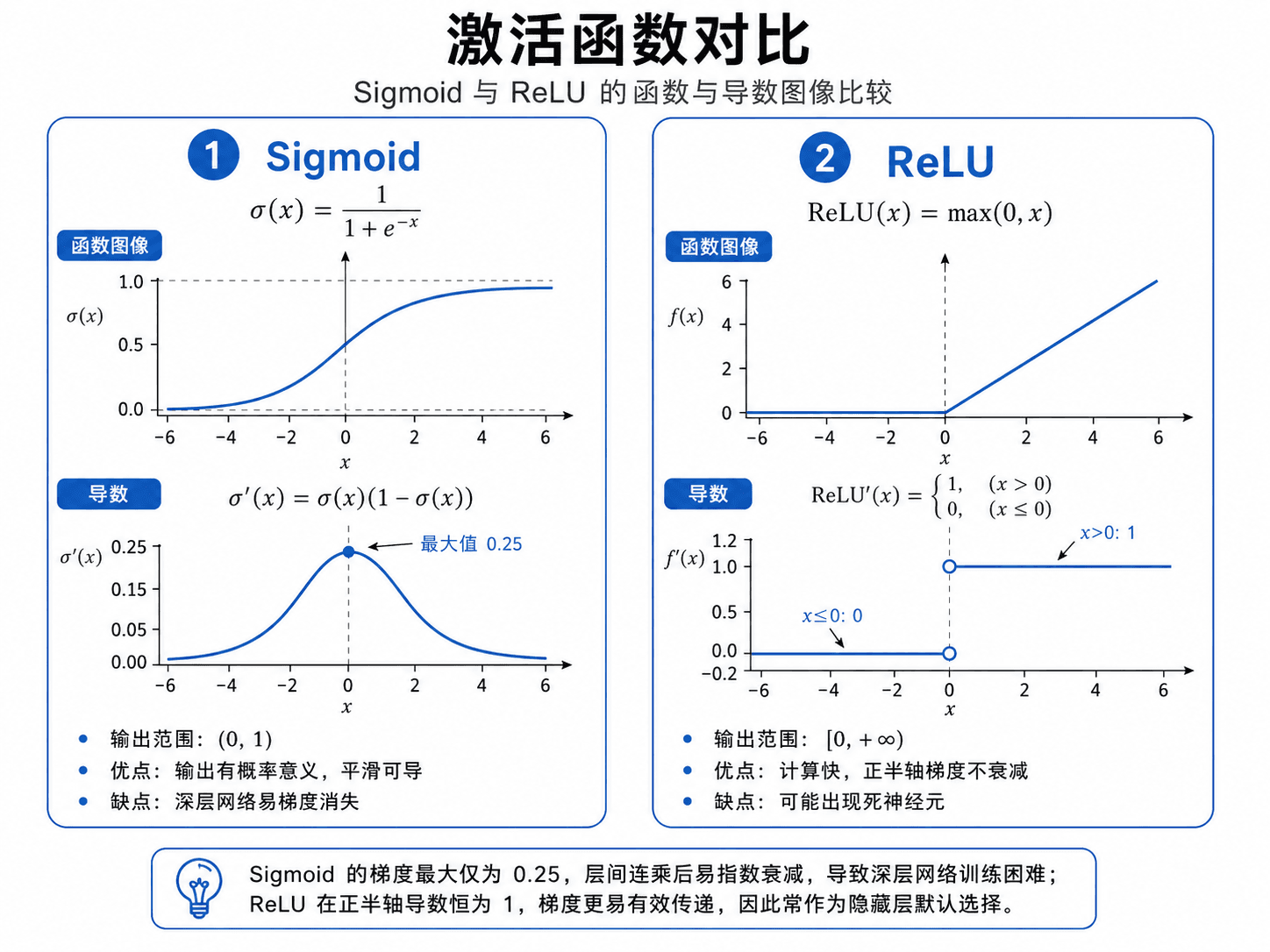
| 属性 | Sigmoid | ReLU |
|---|---|---|
| 公式 | ||
| 导数 | ,最大值 0.25 | 时为 1, 时为 0 |
| 输出范围 | ||
| 优点 | 输出有概率意义,平滑可导 | 计算快,正半轴不会梯度消失 |
| 缺点 | 梯度消失(深层网络梯度指数衰减) | 死神经元(负输入永远输出 0) |
| 适用场景 | 输出层(二分类概率) | 隐藏层(现代网络默认选择) |
Sigmoid 的梯度最大才 0.25,连乘几层后指数衰减到接近 0,深层参数几乎学不动。ReLU 在正半轴导数恒为 1,梯度无衰减地传回去,所以成了隐藏层的默认选择。
MNIST 每张图 28x28 灰度图像,展平后 784 维。一个典型 MLP:
784 (输入) ──> 100 (隐藏层, ReLU) ──> 10 (输出, Softmax)
参数量:。准确率约 88%。还行,但有一个根本性问题。
MLP 把 28x28 图像展平成 784 维向量,空间结构信息全部丢失。一个像素在左上角还是右下角,MLP 完全看不出区别。另外参数量也随图像尺寸爆炸——换成 224x224 的输入就不可接受了。
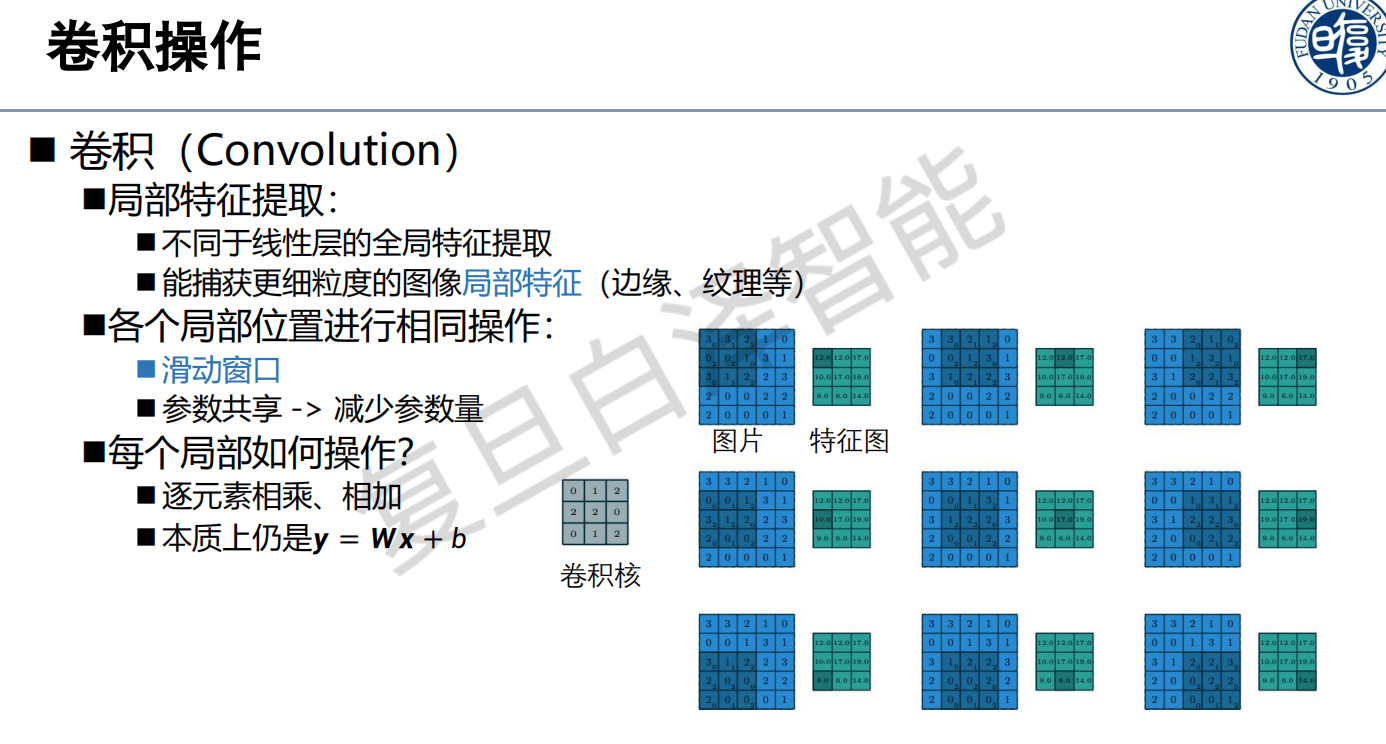
CNN 用小的卷积核(如 5x5)在图像上滑动,每个位置做逐元素乘加:
输入图像(局部) 卷积核 输出(一个值)
+---+---+---+ +---+---+---+
| 1 | 0 | 1 | | 1 | 0 | 1 |
+---+---+---+ +---+---+---+
| 0 | 1 | 0 | * | 0 | 1 | 0 | = 1+0+1+0+1+0+1+0+1 = 5
+---+---+---+ +---+---+---+
| 1 | 0 | 1 | | 1 | 0 | 1 |
+---+---+---+ +---+---+---+
三个好处:
- 参数共享:同一个卷积核在所有位置复用,5x5 的核只有 25 个参数。
- 局部连接:每个输出只依赖局部区域,天然提取边缘、角点、纹理等局部特征。
- 平移不变性:一个"7"无论写在图像左边还是右边,同一个卷积核都能检测到。
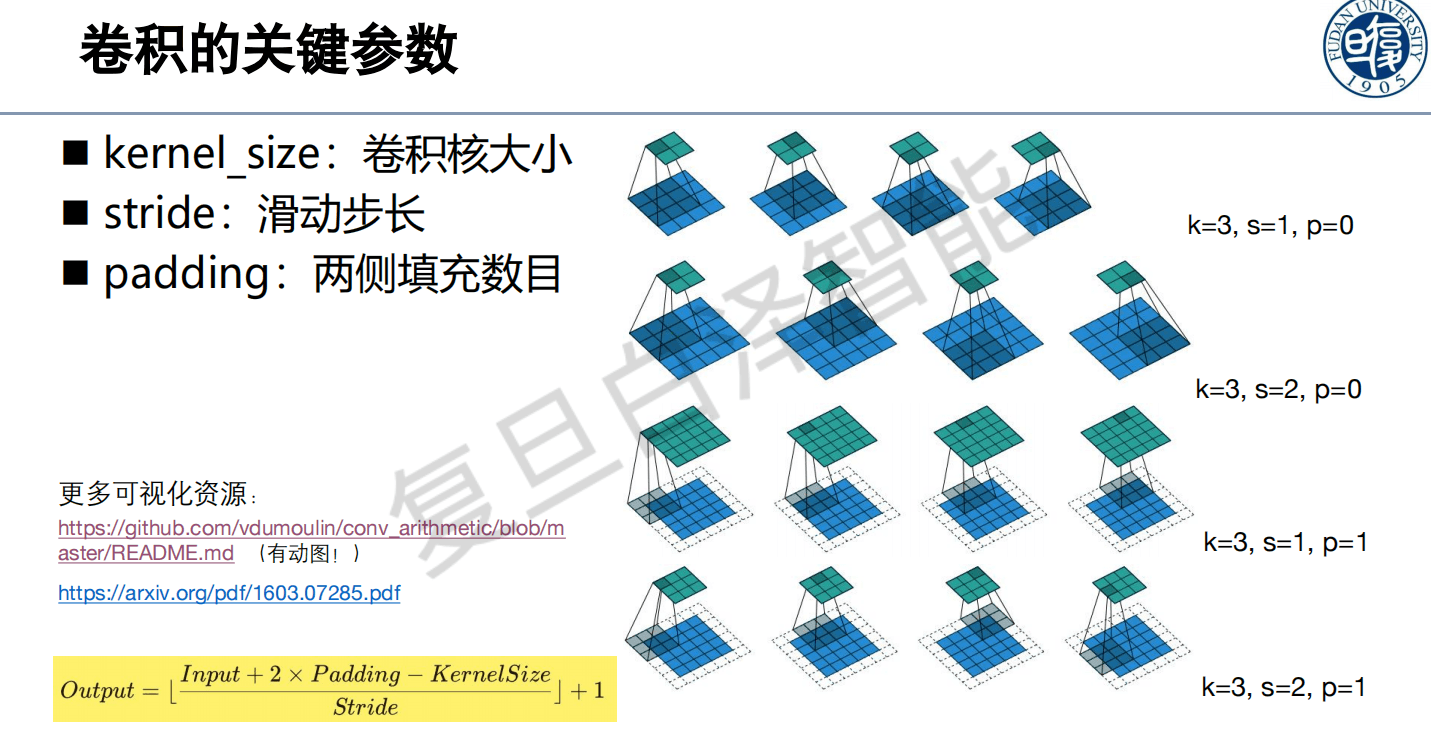
- kernel_size:卷积核尺寸,常用 3x3 或 5x5
- stride:滑动步长,stride=2 输出尺寸减半
- padding:边缘补零圈数
输出尺寸公式:
28x28 输入,5x5 核,stride=1,padding=0,输出 ,即 24x24。
卷积后通常接 2x2 最大池化:每个 2x2 区域取最大值,输出尺寸减半。目的是降维和增强鲁棒性。
| 维度 | MLP | CNN |
|---|---|---|
| 输入处理 | 展平为一维向量 | 保留二维空间结构 |
| 连接方式 | 全连接 | 局部连接 + 参数共享 |
| 参数量 | 大(与输入维度成正比) | 小(卷积核共享) |
| 平移不变性 | 无 | 有 |
| MNIST 准确率 | ~88% | ~96-98% |
| 适用场景 | 表格数据、低维特征 | 图像、语音等有空间结构的数据 |
LeNet-5 是 Yann LeCun 在 1998 年提出的 CNN 架构 [LeCun et al., 1998],专为手写数字识别设计。它确立了 CNN 的基本范式:卷积-激活-池化的堆叠加全连接分类头。
输入 Conv1 Pool1 Conv2 Pool2 Flatten FC1 FC2 FC3
[B,1,28,28] -> [B,6,24,24] -> [B,6,12,12] -> [B,16,8,8] -> [B,16,4,4] -> [B,256] -> 120 -> 84 -> 10
k=5,s=1 2x2 max k=5,s=1 2x2 max
+ReLU +ReLU
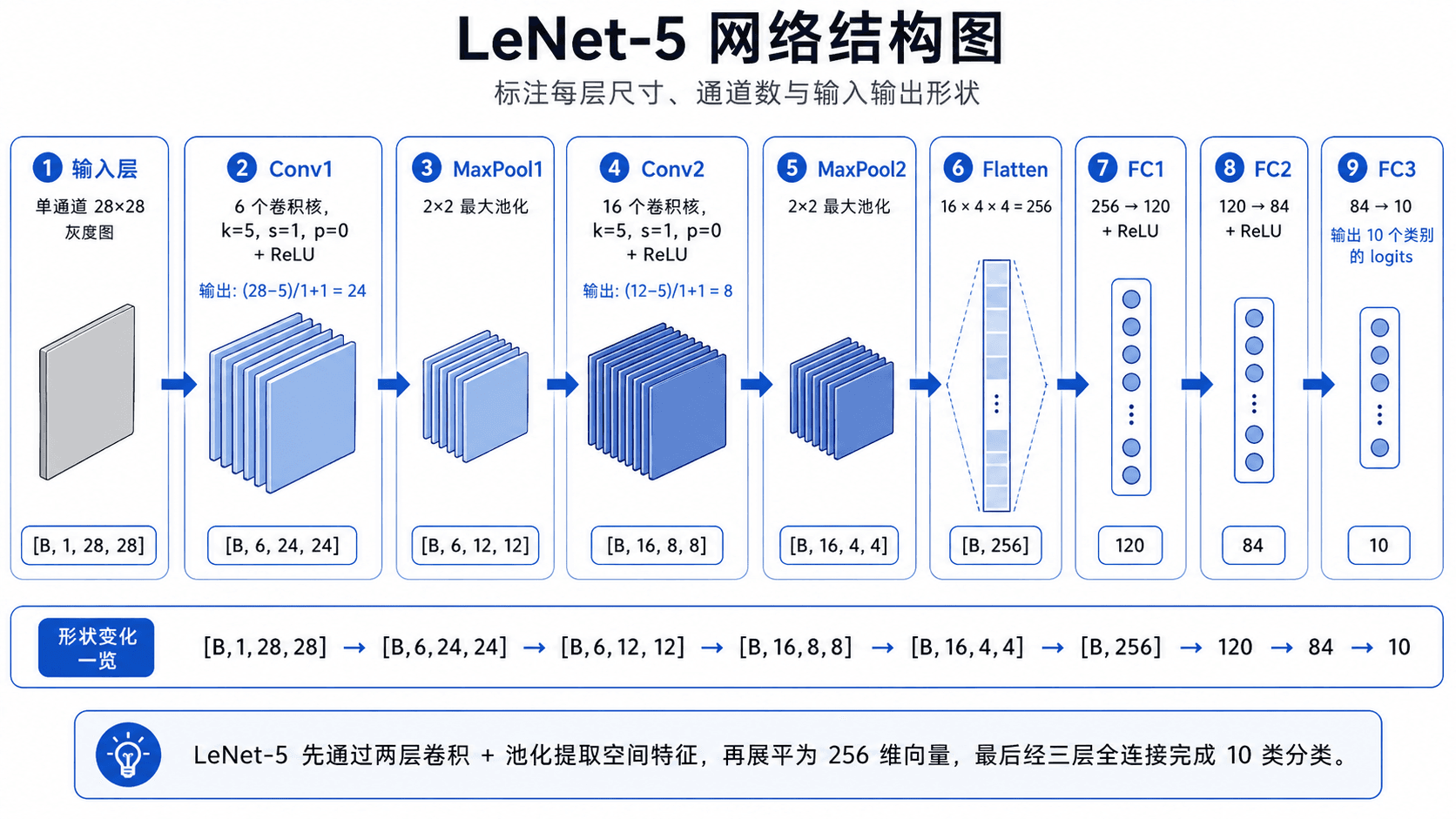
- 输入层:
[B, 1, 28, 28]— 单通道 28x28 灰度图 - Conv1:6 个 5x5 卷积核,stride=1,无 padding。输出 ,形状
[B, 6, 24, 24] - ReLU + MaxPool1:2x2 最大池化,输出
[B, 6, 12, 12] - Conv2:16 个 5x5 卷积核。输出 ,形状
[B, 16, 8, 8] - ReLU + MaxPool2:2x2 最大池化,输出
[B, 16, 4, 4] - Flatten:,形状
[B, 256] - FC1:256 → 120,带 ReLU
- FC2:120 → 84,带 ReLU
- FC3:84 → 10(输出 10 个类别的 logits)
| 层 | 计算 | 参数数 |
|---|---|---|
| Conv1 | 156 | |
| Conv2 | 2,416 | |
| FC1 | 30,840 | |
| FC2 | 10,164 | |
| FC3 | 850 | |
| 总计 | 44,426 |
总共不到 4.5 万个参数——比 MLP 的 7.9 万还少,准确率却从 88% 跃升到 96-98%。空间先验的效果立竿见影。
PyTorch 中定义模型继承 nn.Module,实现 __init__(声明各层)和 forward(定义前向传播路径)。
LeNet-5 的完整定义:
class LeNet5(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 6, kernel_size=5) self.conv2 = nn.Conv2d(6, 16, kernel_size=5) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(16 * 4 * 4, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) # [B,1,28,28] -> [B,6,12,12] x = self.pool(F.relu(self.conv2(x))) # -> [B,16,4,4] x = x.view(x.size(0), -1) # -> [B,256] x = F.relu(self.fc1(x)) # -> [B,120] x = F.relu(self.fc2(x)) # -> [B,84] x = self.fc3(x) # -> [B,10] return x
15 行代码,每一行对应架构图中的一步。
训练循环的核心是三行代码,顺序不能乱:
model = LeNet5() optimizer = optim.Adam(model.parameters(), lr=1e-3) criterion = nn.CrossEntropyLoss() for epoch in range(num_epochs): for images, labels in train_loader: outputs = model(images) # 前向传播 loss = criterion(outputs, labels) # 计算损失 optimizer.zero_grad() # 1. 清零旧梯度 loss.backward() # 2. 反向传播算新梯度 optimizer.step() # 3. 更新参数
三步的含义:
zero_grad():PyTorch 默认累加梯度,必须手动清零。backward():从 loss 出发沿计算图反向传播,算出每个参数的梯度。step():用梯度更新参数(Adam 还会自动调整每个参数的步长)。
注意 nn.CrossEntropyLoss 内部已包含 Softmax,所以 forward 最后一层直接输出 logits,不需要手动加 Softmax。
| 要点 | 说明 |
|---|---|
| 有监督学习四步闭环 | 数据 → 模型 → 损失 → 梯度下降,后续的攻击和防御都在这个框架里操作 |
| MLP 的局限 | 丢弃空间结构,参数量大,MNIST 上约 88% |
| CNN 的空间先验 | 参数共享、局部连接、平移不变性,LeNet-5 用更少参数达到 96%+ |
| PyTorch 训练范式 | nn.Module 定义模型,zero_grad → backward → step 更新参数 |
下一篇讨论对抗样本:攻击者不更新模型参数,而是沿梯度方向修改输入图像,让模型自信地做出错误判断。梯度下降是学习的工具,反过来也是攻击的武器。
- LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. https://www.deeplearningbook.org/